
The Java Map interface is a powerful data structure for handling key-value pairs. Present in the java.util package, it’s ideal for managing data associations where each key maps to a specific value. Common use cases include counting occurrences (e.g., word frequency in text), grouping data (e.g., products by category), or accessing items by specific identifiers (e.g., user IDs).
This post is about understanding the purpose, key implementations, common operations, and practical scenarios for using Java Map.

The Java Map interface stores data in key-value pairs, which makes it different from other collections such as List and Set. Each key in a map is unique, meaning no duplicate keys are allowed. However, values can be duplicated. Additionally, HashMap, which is an implementation of Map, permits null values and even a null key.
The following classes implement the Java Map interface, each with unique characteristics:
The below diagram shows the Java Map hierarchy:
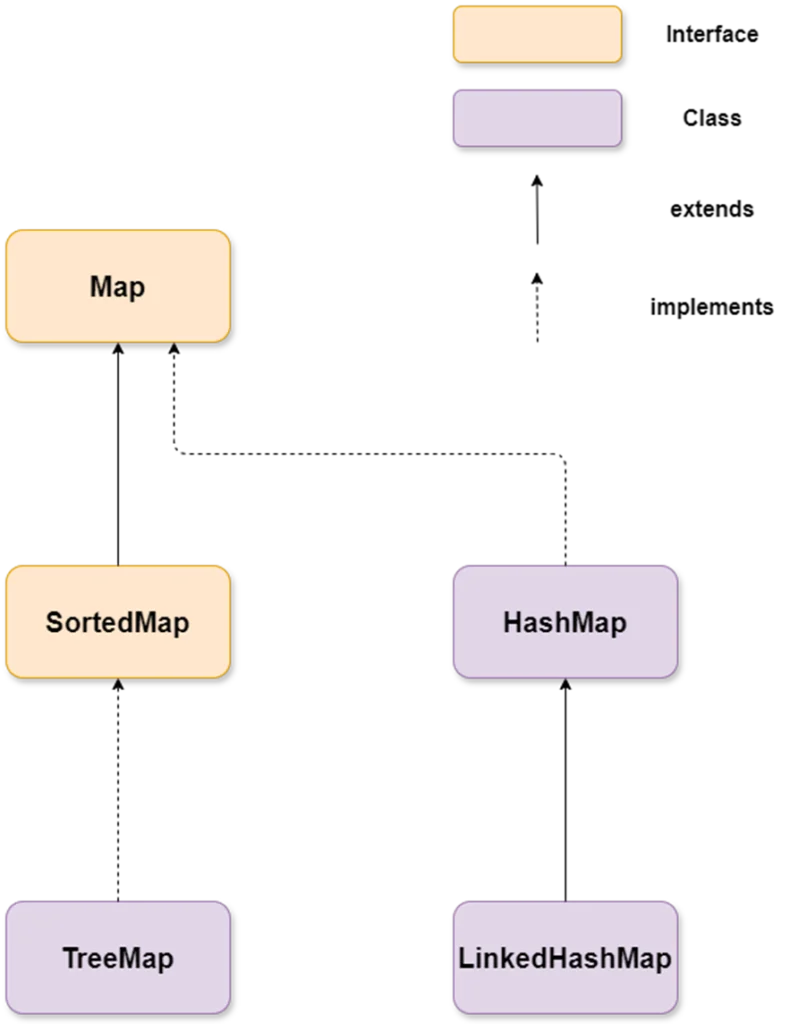
The Map interface is often misunderstood as being a subtype of the Collection interface. However, this isn’t true. Map is a part of the Java Collections Framework but doesn’t extend the Collection interface due to the unique structure and specialized purpose of Map.
Lacking certain collection methods like add and remove, Map doesn’t extend Collection. Map’s role is as a data structure focused on efficient mapping and retrieval rather than element storage alone.
Java doesn’t allow you to create objects of interfaces; hence, you can’t create an object of the Map interface directly. To create a map, you need to create an object of one of its implementation classes. Here’s an example showing how you can create a map in Java using HashMap:
import java.util.HashMap;
import java.util.Map;
public class SimpleMapExample {
public static void main(String[] args) {
Map<String, Integer> simpleMap = new HashMap<>();
}
}The simpleMap will store String keys and Integer values as declared above.
As mentioned above, Java provides multiple implementations of the Map interface, each with unique properties suited to specific use cases. Here’s an overview of common use cases for each Map class. Since implementations have specific strengths, selecting the ideal Map class for each use case is it easy.
HashMap is one of the most widely used implementations of Java Map due to its speed and flexibility. HashMap stores entries in an unordered manner, meaning the insertion order of elements isn’t preserved. With the versatility to allow one null key and multiple null values, HashMap is useful for many applications. However, synchronization isn’t supported, so HashMap isn’t safe for concurrent access without external synchronization.
Let’s see an example by creating a HashMap to store and retrieve student IDs and names.
import java.util.HashMap;
import java.util.Map;
public class HashMapExample {
public static void main(String[] args) {
Map<Integer, String> studentMap = new HashMap<>();
studentMap.put(101, "Alice");
studentMap.put(102, "Bob");
studentMap.put(103, "Charlie");
System.out.println("Student ID 102: " + studentMap.get(102));
}
}As seen in the Map hierarchy, LinkedHashMap extends HashMap but maintains the order of insertion. This makes the function highly useful when the order of elements matters, such as in a caching system or tracking the sequence of user actions. Similar to HashMap, LinkedHashMap allows null keys and values.
Let’s take a look at an example. Here, LinkedHashMap keeps track of the order of recent actions.
import java.util.LinkedHashMap;
import java.util.Map;
public class LinkedHashMapExample {
public static void main(String[] args) {
Map<Integer, String> recentActions = new LinkedHashMap<>();
recentActions.put(1, "Login");
recentActions.put(2, "Viewed Profile");
recentActions.put(3, "Added to Cart");
System.out.println("Recent actions: " + recentActions);
}
}TreeMap sorts its keys in natural order (ascending) or based on a custom comparator. This makes TreeMap ideal for scenarios where you need sorted key access, such as maintaining a leaderboard or other sorted data structures. Unlike HashMap and LinkedHashMap, TreeMap doesn’t allow null keys, but it allows null values.
Here’s an example where we’re using TreeMap to create a leaderboard that ranks scores in ascending order.
import java.util.Map;
import java.util.TreeMap;
public class TreeMapExample {
public static void main(String[] args) {
Map<Integer, String> leaderboard = new TreeMap<>();
leaderboard.put(500, "Alice");
leaderboard.put(750, "Bob");
leaderboard.put(300, "Charlie");
System.out.println("Leaderboard: " + leaderboard);
}
}The Map interface provides several methods to manage key-value pairs efficiently. Let’s discuss some of the most commonly used operations in Map.
The Map interface provides the put method to add a new key-value pair to the map. If the key already exists, it updates its value.
import java.util.HashMap;
import java.util.Map;
public class MapOperationsExample {
public static void main(String[] args) {
Map<String, Integer> ageMap = new HashMap<>();
ageMap.put("Alice", 30);
ageMap.put("Bob", 25);
ageMap.put("Charlie", 35);
System.out.println("Ages: " + ageMap);
}
}Here, we added three entries to the map, storing names as keys and ages as values.
To retrieve a value associated with a specific key, use the get method. If the key isn’t found, get returns null.
System.out.println("Alice's age: " + ageMap.get("Alice"));This retrieves and prints the value associated with the key Alice.
As mentioned above, you can update a value in a map by calling put again with the existing key and a new value.
ageMap.put("Alice", 31); // Update Alice's age
System.out.println("Updated Ages: " + ageMap);Here, we update the age of Alice to 31.
The remove method deletes an entry based on its key. If the key exists, it removes the key-value pair and returns the value; if not, it returns null.
ageMap.remove("Bob");
System.out.println("After removal: " + ageMap);This removes the entry for Bob from the map.
We can use the containsKey and containsValue methods to check if a key or value is present in the map respectively.
boolean hasCharlie = ageMap.containsKey("Charlie");
boolean ageExists = ageMap.containsValue(31);
System.out.println("Contains 'Charlie' as a key? " + hasCharlie);
System.out.println("Contains '31' as a value? " + ageExists);These methods help verify the presence of keys or values without retrieving or modifying entries and can save you from a potential NullPointerException.
Whenever you want to access all keys, values, or key-value pairs of a map, you’ll need to iterate over it. Java Map provides several iteration techniques to do so. Each of these techniques offers a distinct advantage based on the type of iteration required. Choosing the right method can improve code readability and efficiency.
The entrySet method returns a set of all key-value pairs in the map, which is efficient for accessing both keys and values simultaneously.
for (Map.Entry<String, Integer> entry : ageMap.entrySet()) {
System.out.println("Name: " + entry.getKey() + ", Age: " + entry.getValue());
}If you only need keys or values, using keySet or values is more concise. keySet returns a set of all keys, while values returns a collection of all values.
// Iterate over keys
for (String name : ageMap.keySet()) {
System.out.println("Name: " + name);
}
// Iterate over values
for (Integer age : ageMap.values()) {
System.out.println("Age: " + age);
}If you’re using Java 8 or later versions, the forEach method with lambda expressions offers a concise way to iterate over entries. This method is handy for quickly printing or modifying entries in a single line.
ageMap.forEach((name, age) -> System.out.println("Name: " + name + ", Age: " + age));Java 8 introduced several helpful methods in the Map interface, making common operations more efficient and concise.
int age = ageMap.getOrDefault("Ashutosh", 23); // Returns 23 if "Ashutosh" key isn't foundageMap.putIfAbsent("Ashutosh", 23);ageMap.computeIfPresent("Ashutosh", (k, v) -> v + 1); // Increments the value if the key "Ashutosh" was presentThese methods reduce boilerplate code, improve readability, and make Map handling more efficient.
Now that you understand the basics of Java Map, let’s review some best practices and performance considerations.
Choosing the right Java Map implementation is critical for better performance. HashMap is ideal for most cases due to fast access times. LinkedHashMap is better if insertion order matters. TreeMap is useful for sorted maps, although it’s slower due to its red-black tree structure.
Handling nulls can lead to issues; consider using Optional or getOrDefault to avoid.
NullPointerException. A very common exception called ConcurrentModificationException arises when the Map changes during an iteration (for example, adding or removing elements). To prevent this exception, consider using thread-safe maps like ConcurrentHashMap. Unlike traditional HashMap, ConcurrentHashMap allows multiple threads to safely read and write at the same time. ConcurrentHashMap divides its entries into segments, so only certain parts are locked during updates, which reduces waiting times and is faster in multithreaded programs.
Understanding these best practices helps maintain efficient and reliable map operations, especially in concurrent enterprise applications.

Efficient usage of Map is crucial in Java applications, especially when maps handle frequent reads/writes or large amounts of data. Poorly optimized maps can increase memory usage or slow down performance, especially if the map type doesn’t fit the way it’s being used.
But how do you know if you need optimization? This is where monitoring tools like Stackify Retrace kicks in. It can help spot these issues by tracking memory use and processing times. For example, if a HashMap has too many reads/writes, you might consider switching to ConcurrentHashMap for thread safety or LinkedHashMap to keep items in insertion order.
Stackify’s tools Retrace and Prefix offer powerful insights into Java Map usage. Prefix enables real-time tracking of Map operations, displaying execution times and call frequency to help developers spot bottlenecks early. For more in-depth analysis, Retrace monitors performance issues by identifying inefficient Map usage, potential memory leaks, and heavy operations that may need attention.
For more on tracking Java maps, visit Stackify’s Java APM Overview or explore Java APM troubleshooting for optimization tips. To integrate monitoring in Java applications, follow Stackify’s Java Set Up Guide to integrate monitoring in Java applications.
Java Maps are powerful tools for organizing data using key-value pairs, making storing, searching, and retrieving information easy. Choosing the right type of Map and using it effectively can boost your app’s performance. To keep your application running smoothly, leverage tools like Stackify with real-time monitoring to help you spot areas that need improvement.
If you’re interested in optimizing all your Java applications, start your free Stackify trial today and explore performance-tuning the Stackify way.
Stackify's APM tools are used by thousands of .NET, Java, PHP, Node.js, Python, & Ruby developers all over the world.
Explore Retrace's product features to learn more.









