
Currently, Python is the most used programming language for different projects around the world. According to statistics, 44.1% of programmers choose Python coding language for application/web development. However, that does not mean that Python developers are exempt from creating messy and inefficient code that can cost you and your clients time and money This is where Python code optimization comes in.
Let’s start by defining code optimization, so that you get the basic idea and understand why it’s needed. Sometimes it’s not enough to create code that just executes the task. Large and inefficient code can slow down the application, lead to financial losses for the customer, or require more time for further improvements and debugging.
Python code optimization is a way to make your program perform any task more efficiently and quickly with fewer lines of code, less memory, or other resources involved, while producing the right results.
It’s crucial when it comes to processing a large number of operations or data while performing a task. Thus, replacing and optimizing some inefficient code blocks and features can work wonders:
There are certain scenarios where Python can lead to performance issues. Alternately, some situations may demand additional code manipulation to optimize your Python code due to the nature of operation being performed. Let’s explore some common performance issues in Python which will help us understand why we need optimization in the first place?
A lot of times you’ll need to write code that does intensive calculations, complex mathematical operations and data manipulation which can be CPU intensive. In such cases, using Python’s interpreter will give you a slower execution time as compared to compiled languages.
When dealing with long-running processes or large datasets, Python’s inefficient memory management can be inefficient can lead to excessive memory consumption. As a result, your code can execute slower than usual and may also cause a crash at times.
Dealing with operations such as reading and writing to files, making network requests or interacting with the database, can slow down your Python code.
Sometimes, due to either a lack of knowledge or experience, Python developers use inappropriate data structures which can cause performance issues. For instance, using lists when sets or dictionaries would be more efficient can cause slower lookups and inserts.
The choice of algorithms and data processing techniques can significantly impact performance. Using algorithms with higher time complexity (e.g., nested loops) when more efficient alternatives exist can lead to slow execution.
Python strings are immutable, and operations like string concatenation in loops can result in significant performance overhead due to the creation of new string objects.
Overusing global variables can slow down your code since Python has to look up these variables in a global namespace, which is slower than accessing local variables.
Python’s Global Interpreter Lock (GIL) restricts the execution of multiple threads in CPython, the reference implementation. This can limit the parallelism of multi-threaded applications, making them slower than expected.
Python provides many built-in functions and libraries for common tasks. Failing to leverage these can lead to slower code due to reinventing the wheel.
Using external libraries or packages that are not optimized for performance can impact your code’s efficiency. It’s crucial to choose well-maintained and optimized libraries when possible.

Python developers need to be able to use code optimization techniques instead of basic programming to ensure applications run smoothly and quickly. Below we have listed 6 tips on how to optimize Python code to make it clean and efficient.
To better understand the Peephole optimization technique, let’s start with how the Python code is executed. Initially the code is written to a standard file, then you can run the command “python -m compileall <filename>”and get the same file in *.pyc format which is the result of the optimization.
<Peephole> is a code optimization technique in Python that is done at compile time to improve your code performance. With the Peephole optimization technique, code is optimized behind the scenes and is done either by pre-calculating constant expressions or by using membership tests. For example, you can write something like the number of seconds in a day as a = 60*60*24 to make the code more readable, but the language interpreter will immediately perform the calculation and use it instead of repeating the above statement over and over again and thereby reducing the software performance.
The result of the Peephole optimization technique is that Python pre-calculates constant expressions 60*60*24, replacing them with 86400. So even if you write 60*60*24 all the time, it won’t decrease performance.
Using this technique, you can replace a section of the program or a segment of instruction without significant changes in output.
Applying the optimization technique, you can:
Pay attention to the fact that this transformation can only be performed by Python for literals. Thus, the optimization will not happen if any of the sets or lists used are not literals.
Let’s take a look at some examples:
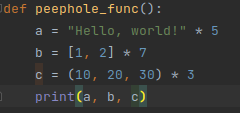
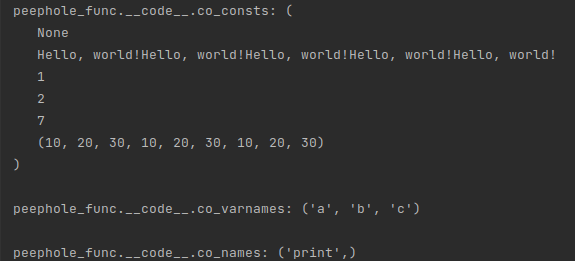
String objects in Python are sequences of Unicode characters, so they are called “text” sequences in the documentation. When characters of different sizes are added to a string, its total size and weight increase, but not only by the size of the added character. Python also allocates extra information to store strings, which causes them to take up too much space. To increase efficiency, an optimization method called string interning is used.
The idea behind string interning is to cache certain strings in memory as they are created. This means that only one instance of a particular string is active at any given time, and no new memory is needed to refer to it.
String interning has a lot in common with shared objects. When a string is interned, it is treated as a shared object because an instance of that string object is globally shared by all programs running in a given Python session.
As the most common implementation of the Python programming language, CPython loads shared objects into memory every time a Python interactive session is initialized.
This is why string interning allows Python to run efficiently, both in terms of saving time and memory.
Python tends to store only those strings that are most likely to be reused, namely identifier strings:
Principles according to which a string should be interned:
Thus, all strings that are read from a file or received through the network are not part of the about-interning. However, just offload such a task to the intern() function to start interning such strings and processing them.
By profiling your code, you can identify areas of improvement in your code for further optimization. There are two main ways to do this.
Use stop-watch profiling with this module. <timeit> records the time needed for task execution by a certain code segment and measures the time elapsed in milliseconds.
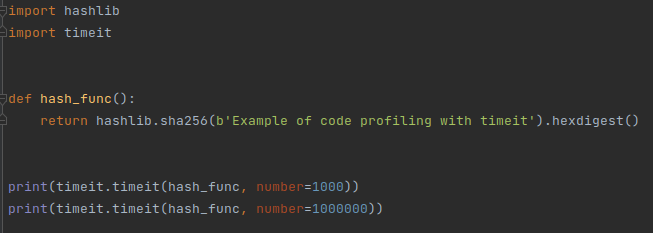
Here’s how it’s calculated:
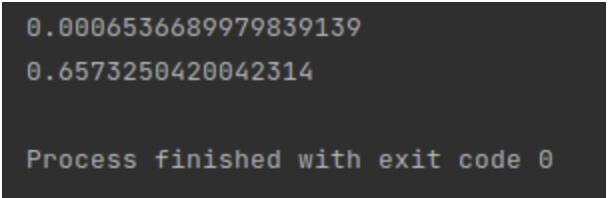

This is advanced profiling, which is part of the Python package since Python 2.5. There are several ways to connect it to the Python code:
Knowing the key elements of the cProfile report, you can find bottlenecks in your code.
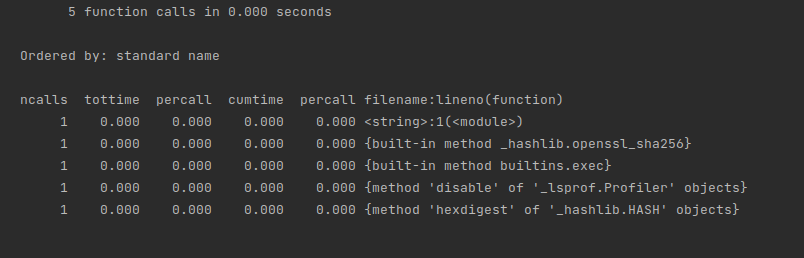
Here are the elements to consider:
<filename_lineno(function)> — a point of action in a program.
This is a way to optimize memory by using such a great tool as generators. Their peculiarity is that they don’t return all items (iterators) at once, but can return only one at a time. It’s better to use keys and the default <sort()> method while sorting items in a list. Thus, for instance, you can sort the list and strings according to the index selected as part of the key argument.
What this might look like:
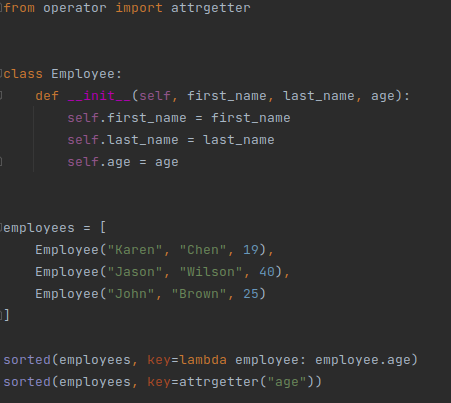
There are thousands of built-in operators and libraries available in Python. It’s better to use the built-ins wherever possible to make your code more efficient. It’s possible due to the fact that all the built-ins are pre-compiled and, thus, pretty fast.
The “C” equivalent of some Python libraries gives you the same features as the original library but with faster performance. So, try to use cPickle instead of Pickle, for example, to see the difference. The PyPy package and <Cython> are a way to optimize a static compiler to make the process even faster.
Globals can have non-obvious and hidden side effects resulting in Spaghetti code. What’s more, Python is slow at accessing external variables. Herewith, it’s better to avoid using them, or at least limit their usage. If they are a necessity, here are a few recommendations:
To optimize method lookup in Python, you can store a reference to a method or function in a local variable rather than repeatedly accessing it through attribute lookup. This can be particularly useful in loops or frequently called functions. Let’s explore this with an example:
# Non-optimized code
for item in my_list:
result = some_object.some_method(item)
# Optimized code
some_method = some_object.some_method # Store a reference
for item in my_list:
result = some_method(item) # Use the local reference
By doing this, you reduce the overhead of attribute lookup on each iteration, potentially improving performance.
String concatenation can be slow, especially when performed in a loop. In such cases, using a list to accumulate parts of the string and then joining them at the end can be much more efficient. Here’s an example:
# Non-optimized code
result = ""
for item in my_list:
result += str(item)
# Optimized code
result_parts = []
for item in my_list:
result_parts.append(str(item))
result = "".join(result_parts)
The optimized code avoids creating unnecessary intermediate string objects during concatenation.

if StatementsMinimizing the number of if statements or optimizing their structure can also improve code performance. Use early returns when possible to avoid unnecessary condition checking.
# Non-optimized code
def process_data(data):
if data:
# Perform some operation
else:
# Handle the empty data case
# Optimized code
def process_data(data):
if not data:
# Handle the empty data case
return
# Perform some operation
In the optimized code, the function avoids the need to check the data condition twice and simplifies the code flow.
It’s critical to create a robust and scalable application that performs tasks rapidly and smoothly. However, it’s impossible to develop such an application by using only basic coding techniques. That’s why you need to optimize the Python code. At the same time, using the optimization techniques described in the article, you can not only create a clean code, but also improve the app performance and save a lot of time and money.
You can also use Stackify’s Retrace performance monitoring and code profiling tool for your Python application. Its Python agent collects performance data and sends it to Retrace. You can also set custom markers or decorators to pinpoint specific areas for monitoring in your code. After running your code, Retrace analyzes data in the Retrace dashboard and finds the bottlenecks for you. Using the insights obtained from Retrace you can optimize your code through restructuring or algorithm improvements.
Bogdan Ivanov is a CTO at DDI development. He is a professional with an advanced degree in Cybersecurity, and 7 years of experience in building a cybersecurity strategy for all the company’s projects. He has a deep understanding of network security, compliance, and operational security.
Stackify's APM tools are used by thousands of .NET, Java, PHP, Node.js, Python, & Ruby developers all over the world.
Explore Retrace's product features to learn more.









