
How is DevOps going within your organization? If you need help measuring its success, we have prepared a list of key DevOps metrics such as MTTR, MTBF, MTTA, and MTTF to track. These metrics can help you understand how your team is doing over time.
The word DevOps means different things to different people. Some say it is a culture, and every vendor in the industry claims that their tools help with DevOps. Depending on how you define DevOps, some of these metrics matter more or less to you and your team.
I define DevOps as everything that relates to deploying and monitoring your applications. In many ways, this bleeds over to site reliability engineering. At Stackify, we don’t even have an operations team with which to collaborate. Our developers deploy directly to the cloud, and we operate in a more “NoOps” style.
Before you figure out what DevOps metrics to track, you need to identify what challenges your organization has and what problems you are trying to solve. At Stackify, our biggest issue has been not deploying often enough and lowering our defect escape rate. Our team is focusing on those specific metrics for 2025, which starts with MTTR.
DevOps is all about continuous delivery and shipping code as fast as possible. You want to move fast and not break things. By tracking these DevOps metrics, you can evaluate how fast you can move before breaking things.
The main goals of DevOps are velocity, quality, and application performance.
You want to ship code as fast and often as possible. The speed at which you can do this will vary greatly based on your type of product, team, and risk tolerance.
Even if you don’t track any DevOps metrics around your velocity, you should at least measure how you are doing on quality. Perhaps you try to ship when you can and don’t care how fast exactly. However, you always care about quality. The last thing you want is always chasing production fires.
The third piece of the equation is performance. You could argue that it is also at odds with your goals of high velocity and quality. Performance is also related to quality, but perhaps a little different.

This metric helps you track how long it takes to recover from failures. A key metric for the business is keeping failures to a minimum and being able to recover from them quickly. It is typically measured in hours and may refer to business hours, not clock hours.
Having good application monitoring tools in place to quickly identify issues and quickly deploy the fix is important to reducing your MTTR.
To calculate MTTR, you divide the total downtime by the number of failure incidents.
You can use MTTR if you want to deploy highly available and reliable applications.
MTTA is a metric used in service level agreements (SLA) and incident response to measure the average time help desk and support teams take to recognize a service request or incident after an alert is sent. Internal stakeholders and customers can set MTTA targets as part of SLA agreements to ensure timely acknowledgment of incidents and complaints.
To calculate MTTA, you divide the total time taken to acknowledge incidents/ number of incidents acknowledged.
A low MTTA indicates a faster acknowledgment of incidents, while a high MTTA indicates delays in acknowledging incidents.
DevOps teams can use MTTA to track responses and monitor if they suffer from alert fatigue.
When problems do happen, it is important to identify them quickly. The last thing you want is to have a major partial or broad system outage and not know about it. Having robust application monitoring and good coverage will help you quickly detect issues. Once you detect them, you also have to fix them quickly!
To calculate MTTD, you divide the total time between failures and detection by the number of failures.
You can use this metric to improve incident detection, resolution, and system reliability.
MTTF is the average time a system is expected to run before it experiences its first failure. It applies to non-reparable systems that can only be replaced once a failure occurs.
To calculate MTTF, you divide the total hours of operation by the total assets in use.
You can use this metric to estimate the lifespan of components or devices that need replacement after failure.
MTBF estimates the average time a repairable technology product remains operational before experiencing expected failures. This reliability metric helps you determine the expected operational uptime of a system before a failure occurs.
MTBF is the total running time divided by the number of failures that occurred over a period of time.
You can use MTBF for systems to estimate when you’ll need to replace technology components.

Tracking how often you do deployments is a good DevOps metric. Ultimately, the goal is to do more smaller deployments as often as possible. Reducing the size of deployments makes it easier to test and release.
I would suggest counting both production and non-production deployments separately. It is also important to consider how often you deploy to QA or pre-production environments. You need to deploy early and often in QA to ensure time for testing. Finding bugs in QA is important to keeping your defect escape rate down.
This might seem like a weird one, but tracking the time it takes to deploy an application is another good metric. One of our applications at Stackify is deployed with Azure worker roles, and it takes about an hour to deploy. It is a nightmare. Tracking such things could help identify potential problems. It is much easier to deploy more often when the task of actually doing it is quick.
If the goal is to ship code quickly, lead time is a key DevOps metric. Lead time is the amount of time that occurs between starting on a work item and it being deployed. This helps you know how long it would take on average until a new work item gets into production if you started today. This is also a good metric to help with BizDevOps.
To increase velocity, it is highly recommended that your team use unit and functional testing extensively. Since DevOps relies heavily on automation, tracking how well your automated tests work is a good DevOps metric. It is good to know how often code changes are causing your tests to break.
Do you know how many software defects are found in production versus QA? If you want to ship code fast, you need to have confidence that you can find software defects before they get to production. Your defect escape rate is a great DevOps metric to track how often those defects make it to production.
The last thing you ever want is for your application to be down. Depending on your type of application and how you deploy it, you may have a little downtime as part of scheduled maintenance. I would suggest tracking that and all unplanned outages.
Tracking error rates within your application is super important. They are an indicator of quality problems, ongoing performance, and uptime issues. Good exception handling best practices are critical for good software.
Errors are a fact of life for most applications. At Stackify, we process millions of messages an hour across several hundred servers and over a thousand SQL databases. A few errors here and there are just part of the noise of a busy system. It is important that you keep a pulse on your error rates and look for spikes.

Before you deploy, you should use a tool like Retrace to look for performance problems, hidden errors, and other issues. During and after the deployment, you should also look for changes in overall application performance.
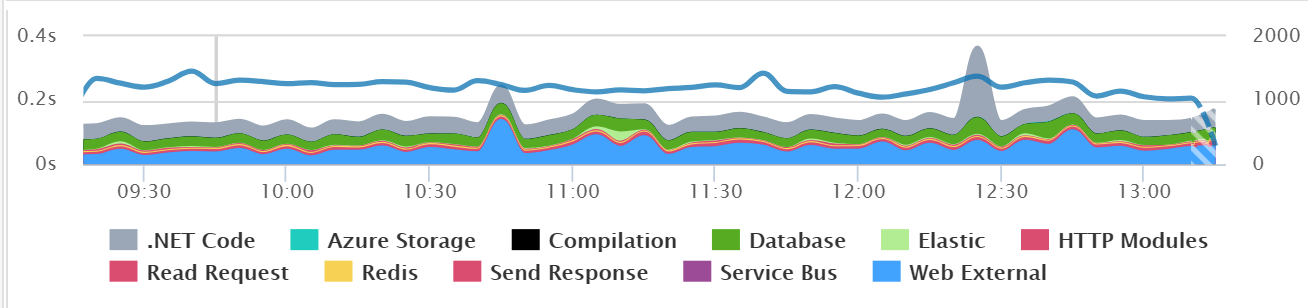
It might be common after a deployment to see major changes in the usage of specific SQL queries, web service calls, and other application dependencies. Tools like Retrace can provide valuable visualizations like the one below that help make it easy to spot problems.
You need to track the percentage of resources in use to enable you optimize infrastructure and ensure efficient use of available resources such as network equipment and servers. This metric is especially useful for Kubernetes and serverless architectures where inefficient resource usage can mean significant costs.
Beyond the DevOps metrics listed above, there are dozens of other metrics you can track that are specific to your applications. Most of them are not necessarily relevant to DevOps in regard to deploying your application. However, they are very critical for monitoring the usage and performance of your applications in production.
For example, at Stackify, we use custom metrics to track how many log messages are received via our API per minute. This is a critical metric that helps us understand the volume of data flowing through our system. Depending on your application, you may have similar custom metrics that are critical to your application.
After a deployment, you will want to keep an eye on all of your critical application metrics to ensure that everything still looks normal.
If you want to take DevOps to the next level, the above list of DevOps metrics will help give you some ideas of what to track and improve. Whether you focus on MTTR, MTFB, MTTA or all of the metrics, performance monitoring tools like Stackify Retrace can help. The goal of DevOps is collaboration and getting developers more involved in the deployment process and application monitoring. If you need some help monitoring your applications, improving MTTR and DevOps success, then your free Retrace trial today.
Stackify's APM tools are used by thousands of .NET, Java, PHP, Node.js, Python, & Ruby developers all over the world.
Explore Retrace's product features to learn more.









