
There are many reasons why Partitioned Tables in SQL Server can be useful. In this post we’re going to focus on just one: deleting large quantities of rows from a tall and narrow SQL table without burninating your Log IO.
Burninating your Log IO you say? Pssshh, Azure SQL can handle this if you work your TSQL like the late Muhammad Ali (rest in peace) worked the ring. Yes, while we could effectively TRUNCATE the entire table in seconds, our goal is to hack a large quantity of rows off while leaving the vast majority of this immense table alone.
No problem, just DELETE FROM WHERE, right? Well, that’s where our Log IO comes into play. As you may already, know Azure SQL runs in Full Recovery Mode by default and currently does not allow adjustments. A DELETE is a logged operation and executing this request on such a large table would not only take an extraordinary amount of time, but it would also “peg” your Log IO usage on your database during processing.
What we need is a way to achieve TRUNCATE like abilities with DELETE like selection criteria.
Say hello to Partitioned SQL Tables, which allow us to accomplish a very similar feat.
Let’s start with this amazing table, which as we already imagined, is somewhere in the neighborhood of 50 million rows, but only contains a handful of columns. First up is the ID column of type INT. Next in line is DateUtc of type DATETIMEOFFSET, where we keep track of when this particular row entered this dimension. Our meat-and-potatoes value column of type INT quickly and unimaginatively rounds up our column list.
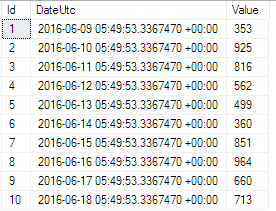
You wouldn’t be making these changes to a live table of the specified size. In our imaginary scenario we’ll be creating a new table for partitioning and then insert our existing data into it.
Let’s start with our Partition Function to define how the Partition column is split into separate table partitions. There are many ways to go about this, but one of my personal favorites is using a rolling-window based on date like the day of the year. If you use a rolling-window based on date, it means your partitions are static and you don’t need to futz around with adding new partitions or splitting existing partitions as your data grows. In this example we’ll be using day of the year, which is effectively 1 to 366.
RANGE LEFT or RANGE RIGHT define whether the values gather from the left or right. For instance, if we used RIGHT, we’d end up with an empty partition before 1 since it gathers only from it’s right. Since we’re using LEFT, we’ll end up with a typically empty/unused partition on the end numbered 366. In more advanced partitioning scenarios LEFT and RIGHT might require more thought (Note: I totally used LINQPad, Enumerable.Range, and String.Join to create that mondo list of day numbers).
CREATE PARTITION FUNCTION [pf_DayOfTheYear](SMALLINT) AS RANGE LEFT FOR VALUES (
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30,
31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60,
61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90,
91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120,
121, 122, 123, 124, 125, 126, 127, 128, 129, 130, 131, 132, 133, 134, 135, 136, 137, 138, 139, 140, 141, 142, 143, 144, 145, 146, 147, 148, 149, 150,
151, 152, 153, 154, 155, 156, 157, 158, 159, 160, 161, 162, 163, 164, 165, 166, 167, 168, 169, 170, 171, 172, 173, 174, 175, 176, 177, 178, 179, 180,
181, 182, 183, 184, 185, 186, 187, 188, 189, 190, 191, 192, 193, 194, 195, 196, 197, 198, 199, 200, 201, 202, 203, 204, 205, 206, 207, 208, 209, 210,
211, 212, 213, 214, 215, 216, 217, 218, 219, 220, 221, 222, 223, 224, 225, 226, 227, 228, 229, 230, 231, 232, 233, 234, 235, 236, 237, 238, 239, 240,
241, 242, 243, 244, 245, 246, 247, 248, 249, 250, 251, 252, 253, 254, 255, 256, 257, 258, 259, 260, 261, 262, 263, 264, 265, 266, 267, 268, 269, 270,
271, 272, 273, 274, 275, 276, 277, 278, 279, 280, 281, 282, 283, 284, 285, 286, 287, 288, 289, 290, 291, 292, 293, 294, 295, 296, 297, 298, 299, 300,
301, 302, 303, 304, 305, 306, 307, 308, 309, 310, 311, 312, 313, 314, 315, 316, 317, 318, 319, 320, 321, 322, 323, 324, 325, 326, 327, 328, 329, 330,
331, 332, 333, 334, 335, 336, 337, 338, 339, 340, 341, 342, 343, 344, 345, 346, 347, 348, 349, 350, 351, 352, 353, 354, 355, 356, 357, 358, 359, 360,
361, 362, 363, 364, 365
)
We need a Partition Scheme as well to define where each Partition lives in storage, which is also used when hooking our table up for partitioning. I’m stashing all data into PRIMARY. Take that data file.
CREATE PARTITION SCHEME [ps_DayOfTheYear] AS PARTITION [pf_DayOfTheYear] ALL TO ([PRIMARY])Now we need a column in the table to represent the partition assignment for each row. I’ve added a Partition column to our new table of type SMALLINT. Considering our partition column is based on the day of the year, at insert time, there’s no reason to go through the pain of populating it manually. Let’s create a quick User-Defined Function to determine the current day of the year and then add a Default Constraint that applies it auto-magically on insert.
CREATE FUNCTION [dbo].[udf_GetDayOfTheYear] (@input DATETIME = NULL)
RETURNS SMALLINT AS
BEGIN
DECLARE @doty SMALLINT
IF (@input IS NULL)
BEGIN
SELECT @doty = DATEPART(dy, GETUTCDATE())
END
ELSE
BEGIN
SELECT @doty = DATEPART(dy, @input)
END
RETURN @doty
ENDNext let’s hook our fancy, new partitioning into our table. We’ll need to replace our ho-hum primary key with a combination of the existing ID and the new Partition column. Then we just make sure the table targets the partition and we’re golden.
CREATE TABLE [dbo].[Imagination_Partitioned](
[Partition] [smallint] NOT NULL DEFAULT [dbo].[udf_GetDayOfTheYear](DEFAULT),
[Id] [int] NOT NULL,
[DateUtc] [datetimeoffset](7) NOT NULL,
[Value] [int] NOT NULL
CONSTRAINT [PK_Imagination_Partitioned] PRIMARY KEY CLUSTERED
(
[Partition] ASC,
[Id] ASC
)ON ps_DayOfTheYear (Partition)
)
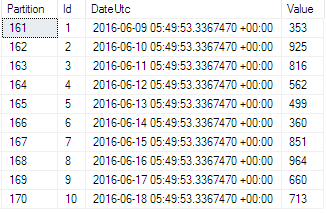
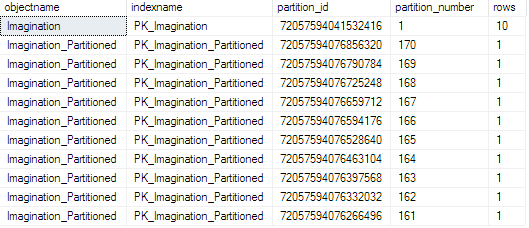
While Imagination has a single partition with all rows, Imagination_Partitioned shows 1 row per partition since each of the 10 rows has a different day of the year assigned via DateUtc. Want to view your own partitioning? No sweat. Here’s how to query your SQL partitions and their size.
SELECT o.name objectname,i.name indexname, partition_id, partition_number, [rows]
FROM sys.partitions p
INNER JOIN sys.objects o ON o.object_id=p.object_id
INNER JOIN sys.indexes i ON i.object_id=p.object_id and p.index_id=i.index_id
WHERE
o.name LIKE '%Imagination%'
AND [rows] > 0
ORDER BY o.name, i.name DESC, partition_number DESC
Exciting, isn’t it? Let’s insert our existing data and see how it looks, before and after.
Before:
After:
Ok, for the grand-finale, let’s create a basic UDF to line-up partitions using a start and end date.
CREATE FUNCTION [dbo].[udf_GetDayOfTheYearRange_FromDate] (@startDate DATETIME, @endDate DATETIME)
RETURNS @results TABLE (Number SMALLINT) AS
BEGIN
DECLARE @partMin SMALLINT = 1
DECLARE @partMax SMALLINT = 365
DECLARE @expectedCount INT = DATEDIFF(DAY, @startDate, @endDate)
IF (@expectedCount < 0)
SET @expectedCount = @partMax + @expectedCount
DECLARE @count INT = 0
DECLARE @current SMALLINT = [dbo].[udf_GetDayOfTheYear](@startDate)
WHILE (@count <= @expectedCount) BEGIN INSERT INTO @results (Number) VALUES (@current) IF (@current >= @partMax)
SET @current = @partMin
ELSE
SET @current = @current + 1
SET @count = @count + 1;
END
RETURN
END
Now we’re ready for a Stored Procedure which can receive a start and end date, retrieve a partition range, and execute our truncates using partitions!
CREATE PROCEDURE [dbo].[sproc_Imagination_TruncatePartitions]
@start DATETIME,
@end DATETIME
AS
BEGIN
SET NOCOUNT ON;
DECLARE @partitions TABLE (Number SMALLINT)
INSERT INTO @partitions SELECT Number FROM dbo.udf_GetDayOfTheYearRange_FromDate(@start, @end)
DECLARE @cnt INT = 0;
SELECT @cnt = COUNT(1) FROM @partitions
WHILE @cnt > 0
BEGIN
DECLARE @partition SMALLINT
SELECT TOP (1) @partition = Number FROM @partitions
TRUNCATE TABLE Imagination_Partitioned WITH (PARTITIONS(@partition))
DELETE TOP(1) FROM @partitions
SELECT @cnt = COUNT(1) FROM @partitions
END
END
Take that, Big Data.
Stackify's APM tools are used by thousands of .NET, Java, PHP, Node.js, Python, & Ruby developers all over the world.
Explore Retrace's product features to learn more.









