When developing an application, chances are that it won’t perform as expected on the first run. In order to check what went wrong, developers in general use debuggers. But experienced developers know that if it happens in production, most debuggers won’t be available. Hence, they pepper the source code with logging statements to help their future self debug the next potential bug.
The subject of this post is to describe the range of possible options for Java applications.
In Java, a long time ago, there was no way to log but to use the standard output and standard error respectively through:
Such kind of logging does the job, but logging is an “always on” feature. It lacks flexibility across different dimensions.
In many cases, whether a log should be written or not depends on the environment (development, QA, production, etc.). Let’s imagine a banking application. In production environments – or at least in environments with production data, it’s not desirable to log sensitive information e.g. passwords, account numbers, amount transferred, etc. However, in non-production environments, it might be a precious way to help solve a bug.
It’s very tempting to write everything into the log “just in case”. However, having too much information is similar to having none, because there’s no way to extract useful data. It would be useful to write only important log statements, but be able to enable relevant log statements when a bug happens in a specific area.
By definition, logs are written to the standard output and/or the standard console. In the end, they just print to the console. However, there are a lot of backend systems that might be good targets for logs: messaging systems, event buses, databases, etc. In the absence of dedicated logging capabilities, there must be an adapter between the console and the target system that scrapes the former to feed the later.
| Scraping may be a good strategy in order to move the responsibility of feeding to the adapter from the application. However, in the absence of capability, it’s the only choice available. Options are always good. |
Apache Log4J started as an attempt to remedy the console situation. Log4J introduced many concepts that are reused across subsequent libraries.
To handle the “always-on” nature of the legacy log statements, Log4J was designed around log levels. There are several log level available (e.g. ERROR, INFO, DEBUG), and each log statement must use one of them. At runtime, a single log level is set: log statements with the same or a higher level are executed, the others are canceled.
Different environments can then be configured with different log levels. For example, production-like environments configuration will allow INFO logs and above only, while development environments will allow everything.
A logger is the entry-point into the Log4J library.
The Logger itself performs no direct actions. It simply has a name […]
Loggers are organized into parent-child relationships, via their name. Hence, the ch is the parent logger of the ch.frankel logger, which itself is a parent of ch.frankel.Foo logger.
An appender is responsible to output a log statement to a single destination type.
The ability to selectively enable or disable logging requests based on their logger is only part of the picture. Log4j allows logging requests to print to multiple destinations. In log4j speak, an output destination is called an Appender.
Destinations includes:
If no out-of-the-box appender exists for one’s specific need, it’s not an issue: the Appender interface allows you to create your own implementation for specific needs.
| Some appenders also offer specific features. For example, regarding the file appender, one of the most important ones is asynchronous writing. Because writing in a file is a blocking operation, log writing can become the bottleneck of an application. While logging is an important feature, it’s not a core business one. Asynchronous writing makes it possible to buffer log statements in memory, and have a dedicated thread to write them in batches. |
Log4J started to get traction and became nearly ubiquitous. Pressure started to mount to embed similar logging capabilities inside the Java API itself. Thus, JDK 1.4 included the java.util.logging package.
This was not the end of it all, though.
A problem regarding JUL was that some log levels didn’t have specific semantics e.g.FINER, unlike Log4J. Also, the number of log levels was different from Log4J, thus there was no easy one-to-one mapping.
| Log4J | JUL |
|
|
Finally, adapters were severely limited: only console and file are provided out-of-the-box.
Given the limitations and since Log4J was already firmly entrenched by now, JUL never really caught on.
Yet, a few libraries did migrate to the new API. As an application developer, that meant that if you were unlucky enough to use libraries that used both frameworks – Log4J and JUL, you had to configure both.
To reduce that configuration effort, Apache Commons Logging was born:
The Logging package is an ultra-thin bridge between different logging implementations. A library that uses the commons-logging API can be used with any logging implementation at runtime. Commons-logging comes with support for a number of popular logging implementations, and writing adapters for others is a reasonably simple task. — Apache Commons Logging
In the end, however, that just complicated the whole situation, as some libraries used Commons Logging, some JUL, and then most Log4J.

Meanwhile, Log4J had become feature complete: development had stopped.
Ceki Gülcü, Log4J’s main contributor, started to work on an un-official “Log4J v2” outside of the Apache Foundation. The main goal was to fix Log4J’s main problem: coupling between the API and the implementation. Thus was born Simple Logging Facade For Java – SLF4J.
The architecture of SLF4J takes advantage of the Java Service Loader mechanism: it allows it to work with abstractions, and to use the implementation provided at runtime on the classpath.
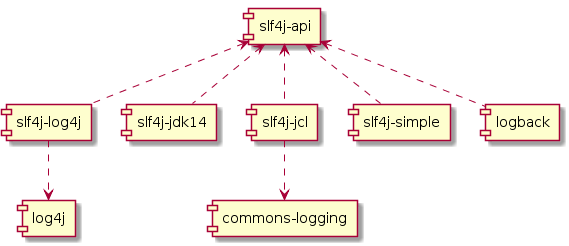
In essence, at compile-time, use SLF4J API, and any desired library at runtime. Out-of-the-box libraries include:
| JAR | DESCRIPTION |
| slf4j-log4j | Redirects calls from SLF4J to Log4J |
| slf4j-jdk14 | Redirects calls from SLF4J to JUL |
| slf4j-jcl | Redirects calls from SLF4J to Java Commons Logging |
| slf4j-simple | Write logs to the console |
| slf4j-logback | Uses the Logback library |
To allow an easy migration path from any of the previous logging frameworks (Log4J, JUL, or Commons Logging), SLF4J offers bridges to redirect calls from one of them to SLF4J:
| JAR | DESCRIPTION |
| jcl-over-slf4j | Redirects calls from Commons Logging to SLF4J |
| log4j-over-slf4j | Redirects calls from Log4J to SLF4J |
| jul-over-slf4j | Redirects calls from JUL to SLF4J |
Probably because of those bridges, SLF4J became very popular, even more so than Log4J… in some cases, SLF4J used as an API, while Log4J used as an implementation.
Log4J 2 was released in 2014. It offers the same features as other logging frameworks:
The main advantage of Log4J 2 is lazy evaluation of log statements, by taking advantage of Java 8’s lambda.
Imagine the following log statement:
LOGGER.debug("This is an computationally expensive log statement" + slowMethod());
Regardless of the log level, the slowMethod() call will take place, and decrease performance.
Hence, for ages, it was advised to guard the log between an evaluation:
if (LOGGER.isDebug()) {
LOGGER.debug("This is an computationally expensive log statement" + slowMethod());
}
Now, the method is called only if the log level reaches the DEBUG level. However, this introduces some issues:
Log4J 2 solves this issues by changing the method argument from String to Provider<String>. It’s now possible to write the following:
LOGGER.debug(() -> "This is an computationally expensive log statement" + slowMethod());
At this point, the method is only called if the log level is DEBUG.
And yet, I never saw Log4J 2 used, whether in apps or in third-party libraries.
| DisclaimerThe author of this post is also the author of this library. |
SLF4K is a thin Kotlin wrapper around the SLF4J API to lazily evaluate messages and arguments passed to logger methods. It allows the following code:
LOGGER.debug("This is an computationally expensive log statement") {slowMethod()}
The state of logging in Java is a big mess: it’s very fragmented between a small number of frameworks. While some frameworks try to play nicely with some others, it doesn’t solve the issue that using multiple libraries might require using different configuration files.
Retrace can help by correlating logs, errors and APM data to get more intelligence. Sign up for a free 14-day trial today.
Stackify's APM tools are used by thousands of .NET, Java, PHP, Node.js, Python, & Ruby developers all over the world.
Explore Retrace's product features to learn more.









