
One of the most important aspects of developing an efficient system is to have clean, helpful logs that will help you understand what errors are being triggered, and what information is being processed.
When you are first creating an application, you might not know what logging framework will be most suitable for your future needs, or you could simply want your system to remain agnostic regarding the logging implementation to be used.
Furthermore, it’s also quite useful to have the flexibility to not be tied to a specific logging framework.
This is the main purpose of SLF4J (Simple Logging Facade for Java) – a logging abstraction which helps to decouple your application from the underlying logger by allowing it to be plugged in – at runtime.
Of course, the flexibility that such an abstraction provides is the main reason to use SLF4J. Nevertheless, there are quite a lot of other aspects that make this library an appealing logging solution.
You’ll have to log information in almost any class you’ll be working on. The Logging API you choose can’t be complex at all, or it will seriously affect the performance of your application.
Lucky for us, the SLF4J developers made the API really simple and straightforward.
Let’s go ahead and see how your code will look like after you add logging statements:
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class SimpleClass {
Logger logger = LoggerFactory.getLogger(SimpleClass.class);
public String processList(List<String> list) {
logger.info("client requested process the following list: {}", list);
try {
logger.debug("Starting process");
// ...processing list here...
Thread.sleep(5000);
} catch (RuntimeException | InterruptedException e) {
logger.error("There was an issue processing the list.", e);
} finally {
logger.info("Finished processing");
}
return "done";
}
}
There are a couple of things you have to notice in this example.
First of all, even though the signature of the logging methods formerly allowed any kind of Object, they currently recognize only Strings.
Of course, this is a conscious decision. It not only avoids relying on an object to provide a suitable toString implementation, but it also avoids confusion with other more specific method signatures.
We can see an example of this above. To log an error you’ll always have to provide a custom message first, followed by a Throwable object.
If you want to use an object’s toString method, you can do so with parametrized messages, as we did in our first log message.
SLF4J is just an API, and it knows nothing about the underlying logger that manages the logs.
Before going on, you might want to have a look at this previous post in order to get the big picture of the Java logging world.
Let’s start by analyzing how SLF4J connects to these frameworks when the application initializes.
The library will look for bindings (a.k.a. ‘providers’ since version 1.8.0) on the classpath – which are basically implementations of a particular SLF4J class meant to be extended.
The SLF4J distribution ships with bindings for the following loggers:
Additionally, Logback implements SLF4J natively, thus a binding for this logger can be found in the logback-classic artifact within the Logback distribution.
One last SLF4J binding that you have to take into consideration is the one provided by the Apache – the creators of Log4j.
While the SLF4J version uses Log4j 1.2.x, the one submitted by their owners use Log4j2, which makes a huge difference for users. The artifact that includes this binding is the log4j-slf4j-impl.jar, and it doesn’t pull in other optional dependencies.
Let’s see then how would you configure SLF4J with Logback in case you are using Maven to manage your dependencies:
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.2.3</version>
</dependency>
And if later on, you decide to use Log4j, you’ll simply replace the artifact declaration:
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.25</version>
</dependency>
Or if you prefer Log4j2, you’ll add the following three necessary dependencies:
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>2.11.1</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.11.1</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
<version>2.11.1</version>
</dependency>
Naturally, since you’re using the SLF4J API, the code remains unchanged, you don’t even have to recompile your source code. It’s as simple as that.
Note: Spring Boot chose Logback as its preferred alternative. If you add the spring-boot-starter-logging to your dependencies, it will be pulled in by any starter package you use. Then a basic SLF4J+Logback configuration will be automatically generated by Spring.
If you want to use SLF4J+Log4j2 in a Spring application, then you’ll have to exclude the spring-boot-starter-logging dependency and replace it for the spring-boot-starter-log4j2 one.
All these libraries – including the ones mentioned in the previous subsection – depend on slf4j-api, so when you add them to your project, the API artifact will be automatically pulled in together with the corresponding logger, when suitable.
In contrast with the commons-logging library, which relies on runtime binding to figure out which implementation to use, SLF4J uses compile-time binding.
You might be wondering how this is possible. It’s actually very simple. Originally, the library just loaded an org.slf4j.impl.StaticLoggerBinder entity from the classpath.
Each SLF4J binding jar provided a class with that same name so that the framework would simply use it.
Since version 1.8.0, the library employs a similar approach but now using Java’s ServiceLoader mechanism to find the correct backend logger.
With this simple strategy, SLF4J avoids many of the classloading issues that commons-logging faced.
One important aspect you have to take into account is that SLF4J can’t guarantee that the bindings will work properly if their artifact version doesn’t match the API library one. It will even emit a warning message on startup if this is the case.
One of the nice features that provide SLF4J is the possibility to generate parametrized log messages easily and in a performant manner:
logger.info("client {} requested to {} the following list: {}", clientId, operationName, list);
It’s fairly similar to the common String.format approach, but it differs in a critical aspect. While string formatting or concatenation will happen whether the message needs to be logged or not, when you use SLF4J’s parametrized methods you’ll avoid incurring in the cost of parameter construction in case the log statement is disabled.
Furthermore, SLF4J goes even a little bit further. It offers three method signatures for string replacement, using one, two or ‘n’ arguments -using varargs.
Of course, the varargs approach would work in any case, but the first two methods mean a slight improvement in performance. Probably a good decision, having in mind that you will use them in most common scenarios.
There’s one last interesting feature provided by SLF4J’s parametrized messages – the possibility of using Objects as parameters. So if you want to just print an object’s string representation, you can easily do that:
logger.info("{}", myObject);
If you ever had to struggle with a poorly documented library or had to deal with an edge case that nobody covered yet, you’ll certainly understand just how important this aspect is.
Simply put, you’ll find most corner cases and specific scenarios over on StackOverflow.
Also, within the SLF4J documentation itself, you’ll find a section explaining the most common errors and warnings that you might come across when working with this logging abstraction. You should definitely keep it handy in case you have to deal with any of those issues.
One good indication of SLF4J’s popularity is its wide usage in popular libraries and frameworks in the Java ecosystem – such as Spring Boot, or Hibernate which has first-class support for it with minimal configuration changes.
Any server application you develop will typically attend several clients using a pool of threads. Each thread will be dedicated to one client, and will, therefore, have a specific context.
The Mapped Diagnostic Context, or MDC for short, is simply a map managed by the logging framework on a per-thread basis. This map will contain relevant information that might be useful when logging messages.
For example, imagine you are working on a regular server-client architecture. You might want to track easily each client’s transaction. With that objective in mind, let’s see how you can use the MDC mechanism.
Let’s have a look at a simple Spring controller to better understand MDC:
import org.slf4j.MDC;
@RestController
public class SimpleController {
Logger logger = LoggerFactory.getLogger(SimpleController.class);
@GetMapping("/slf4j-guide-mdc-request")
public String clientMCDRequest(@RequestHeader String clientId) throws InterruptedException {
MDC.put("clientId", clientId);
logger.info("client {} has made a request", clientId);
logger.info("Starting request");
Thread.sleep(5000);
logger.info("Finished request");
MDC.clear();
return "finished";
}
}
It’s important to notice the MDC.clear command in this snippet. Since threads in a pool are recycled, if you don’t clear or remove the values you stored, you might end up reusing that data erroneously in other requests.
By using the %X specifier within the pattern layout, you can log automatically the value that corresponds to the specified key, if it’s present in the context.
For example, using a Logback configuration:
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>-%d{-yyyy-MM-dd HH:mm:ss.SSS} -%5p %X{clientId}@%15.15t %-40.40logger{39} : %m%n</pattern>
</encoder>
</appender>
<root level="info">
<appender-ref ref="CONSOLE" />
</root>
</configuration>
Finally, let’s make a couple of requests, and check the final logs:
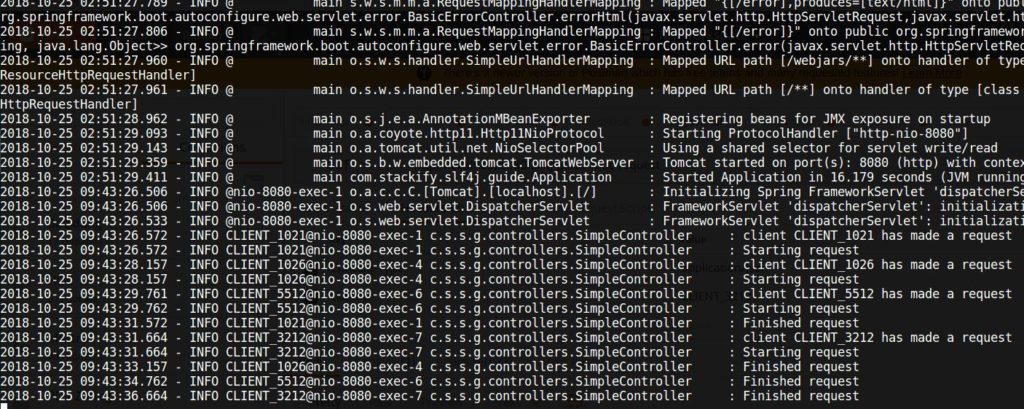
Now it’s really easy to see how your service processed a specific client request.
We have to keep in mind that only Logback and Log4j offer MDC functionality up to this point.
After integrating SLF4J in your application, you might still be using libraries that wrongly configured transitive dependencies to a different logger than the one you want to use.
For these cases, SLF4J provides several artifacts that are in charge of redirecting calls originally destinated to Log4j, JCL, and JUL as if they were made to the SLF4J API:
Note that Logback natively exposes its logger via this API, so there is no need to add any processing layer if the dependency uses that framework.
Of course, when you choose to bridge a logging implementation to SLF4J, you naturally need to avoid using that same framework as our SLF4J backend logger, to avoid loops.
You can use Markers in ‘special’ events or log entries that you want to make them stand out from regular records.
Even though Log4j offers a Marker interface, it’s not compatible with the SLF4J definition. As a result, only Logback supports SLF4J Markers.
Let’s jump to an example that illustrates how you can specify a Marker when you log a message:
import org.slf4j.Marker;
import org.slf4j.MarkerFactory;
public class SimpleController {
Logger logger = LoggerFactory.getLogger(SimpleController.class);
// ...
public String clientMarkerRequest() throws InterruptedException {
logger.info("client has made a request");
Marker myMarker = MarkerFactory.getMarker("MYMARKER");
logger.info(myMarker, "Starting request");
Thread.sleep(5000);
logger.debug(myMarker, "Finished request");
return "finished";
}
}
Apart from the possibility of adding marker data to the log output with the %marker token, you can use the Marker to make filtering decisions.
We won’t see examples of filters since they are out of scope for this article, but feel free to have a look at this previous article where I explained the usage of this capability, among other features that will allow you to get the best out of Logback.
One other piece of functionality you can take advantage of when using Markers is the possibility of triggering emails when the marked event occurs.
SLF4J presents one other library (slf4j-ext.jar) with several helpful tools and features.
One of these extra features is a profiler – which you can use to analyze your system’s performance dynamically by setting ‘stopwatches’ points in your code.
Essentially, you have to indicate when to start counting, and when to stop.
Let’s do that here, to understand how the functionality works:
import org.slf4j.profiler.Profiler;
public class SimpleController {
Logger logger = LoggerFactory.getLogger(SimpleController.class);
// ...
public String clientProfilerRequest() {
logger.info("client has made a request");
Profiler myProfiler = new Profiler("MYPROFILER");
myProfiler.start("List generation process");
List<Integer> list = generateList();
myProfiler.start("List sorting process");
Collections.sort(list);
myProfiler.stop().print();
return "finished";
}
}
Here’s the resulting performance information:
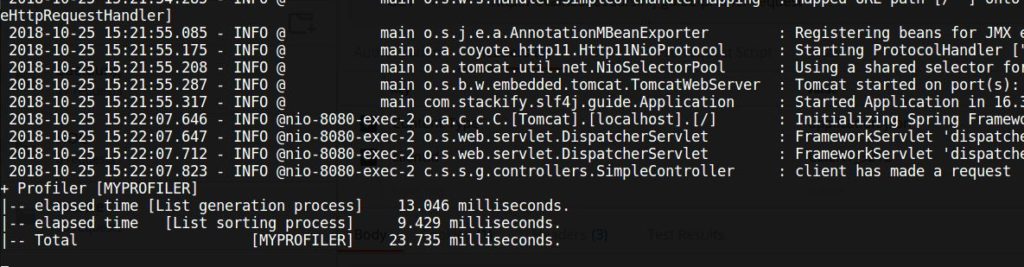
The extension tools also support nested profilers.
This special logger is useful to diagnose issues in your code without the need for a debugging session.
The XLogger class provides functionality to indicate when:
Let’s have a look at one quick example:
import org.slf4j.ext.XLogger;
import org.slf4j.ext.XLoggerFactory;
public class XLoggerController {
private XLogger logger = XLoggerFactory.getXLogger(XLoggerController.class);
// ...
public Integer clientXLoggerRequest(Integer queryParam) {
logger.info("Starting process");
logger.entry(queryParam);
Integer rest = 0;
try {
rest = queryParam % 3;
} catch (RuntimeException anyException) {
logger.catching(anyException);
}
logger.exit(rest);
return rest;
}
}
Then after calling this method twice, you’ll find the next output:

It’s important to notice that XLogger creates TRACE registries for the two most common methods. For catching and throwing methods the logging level is ERROR.
In order to achieve that, we’ll have to create an EventData object with the relevant information and then call the EventLogger.logEvent method passing the object as the parameter:
import org.slf4j.ext.EventData;
import org.slf4j.ext.EventLogger;
public class SimpleController {
Logger logger = LoggerFactory.getLogger(SimpleController.class);
// ...
public String clientEventRequest(String sender, String receiver) {
logger.info("sending from {} to {}", sender, receiver);
// ...sending process...
EventData data = new EventData();
data.setEventDateTime(new Date());
data.setEventType("sending");
String confirm = UUID.randomUUID()
.toString();
data.setEventId(confirm);
data.put("from", sender);
data.put("to", receiver);
EventLogger.logEvent(data);
return "finished";
}
}
You can invoke this method and check the console logs:
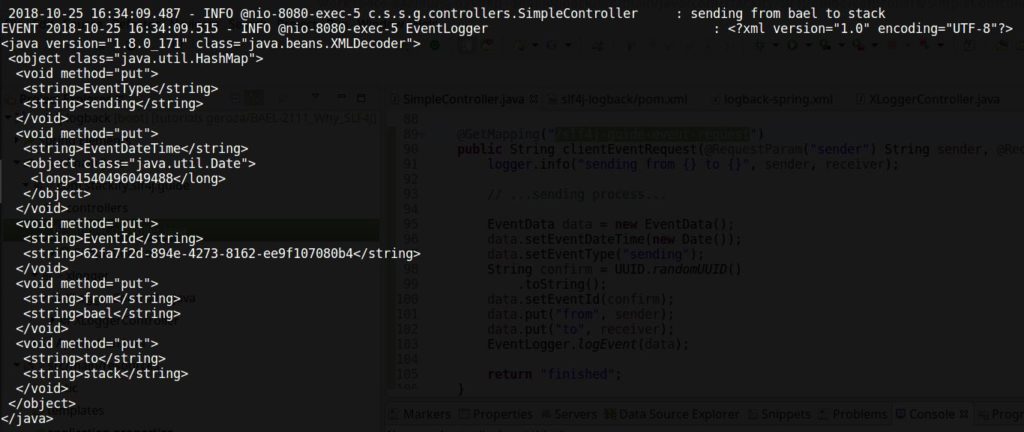
SLF4J provides one additional mechanism to analyze your code by adding log statements to your artifact after it has been compiled with Java Agents.
In this manner, you can add logging to our classes as they are loaded, and still keep our original source code unchanged.
We will omit further details since this tool is still in beta release stage.
If you still want to try it out, or you want to know more about any of the other tools mentioned in this section, feel free to check the SLF4J documentation regarding this subject.
Migrating a whole application to this framework can be a cumbersome and repetitive task, and therefore prone to human errors.
Contemplating this issue, the SLF4J team created a program to aid in this procedure.
The Migrator tool is not actually part of the slf4j-ext bundle, but a Java application itself.
It has a rather simple logic, which executes elementary conversion steps such as replacing import statements and logger declarations.
Thus, you’ll still have to get your hands ‘dirty’, but with the relief of knowing that the most repetitive duties will be done.
The application offers the possibility of selecting from which framework you want to migrate – JCL, Log4j or JUL – by interacting with a wizard.
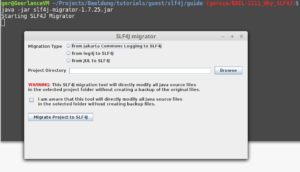
Another interesting feature included in the extension artifact is the localization/internationalization logging support.
This mechanism follows the CAL10N approach – which stands for Compiler Assisted Localization and is used for writing localized messages.
In order to use the CAL10N components, you’ll first have to add the corresponding dependency:
<dependency>
<groupId>ch.qos.cal10n</groupId>
<artifactId>cal10n-api</artifactId>
<version>0.8.1</version>
</dependency>
The next step will be to create an Enum indicating the supported locales and keys of the messages that will be translated:
import ch.qos.cal10n.BaseName;
import ch.qos.cal10n.Locale;
import ch.qos.cal10n.LocaleData;
@BaseName("messages")
@LocaleData({ @Locale("en_US"), @Locale("es_ES") })
public enum Messages {
CLIENT_REQUEST, REQUEST_STARTED, REQUEST_FINISHED
}
Now you need properties files for each locale, where you’ll specify the value for each key. In this example, we’ll have to create two files –messages_es_ES.properties:
CLIENT_REQUEST=El cliente {0} ha realizado una solicitud usando locale {1}
REQUEST_STARTED=Solicitud iniciada
REQUEST_FINISHED=Solicitud finalizada
and messages_en_US.properties:
CLIENT_REQUEST=Client {0} has made a request using locale {1}
REQUEST_STARTED=Request started
REQUEST_FINISHED=Request finished
Pay attention to the pattern of the files names.
With that in place, you’ll proceed to create a LocLogger entity using the desired locale. In this case, and to show the flexibility of this approach, we’ll create the logger dynamically using a method parameter:
import java.util.Locale;
import org.slf4j.cal10n.LocLogger;
import org.slf4j.cal10n.LocLoggerFactory;
import ch.qos.cal10n.IMessageConveyor;
import ch.qos.cal10n.MessageConveyor;
public class SimpleController {
// ...
public String clientLocaleRequest(String localeHeader) {
List<Locale.LanguageRange> list = Locale.LanguageRange.parse(localeHeader);
Locale locale = Locale.lookup(list, Arrays.asList(Locale.getAvailableLocales()));
IMessageConveyor messageConveyor = new MessageConveyor(locale);
LocLoggerFactory llFactory = new LocLoggerFactory(messageConveyor);
LocLogger locLogger = llFactory.getLocLogger(this.getClass());
locLogger.info(Messages.CLIENT_REQUEST, "parametrizedClientId", localeHeader);
locLogger.debug(Messages.REQUEST_STARTED);
locLogger.info(Messages.REQUEST_STARTED);
return "finished";
}
}
Let’s try it out by passing the values es-ES and en-US:
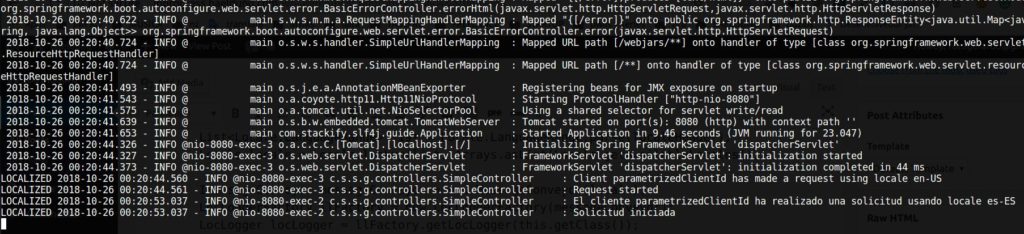
By using the ILoggerFactory entity directly, you can redefine or extend the SLF4J conventions.
It’s important to know about this possibility, but we won’t go into details in this point since the process is explained in this SLF4J FAQ section.
To summarize, SLF4J is one of the most complete logging APIs out there.
It represents a great improvement over commons-logging, avoiding all the classloader issues with a rather simple approach.
Undoubtedly, it has been gaining popularity over the last years, and it will probably stay on that track.
Nevertheless, there are still aspects SLF4J needs to improve, especially regarding compatibility with some Log4j features.
If you want to see the whole working example, you can find it in our Github repo.
Stackify’s Application Performance Mangement tool, Retrace, offers Java users greater application insights with integrated logging and code profiling. With integrated centralized and structured logging, access all of your application logs from a single place across all applications and servers. Start your free, two week trial of Retrace today.
Stackify's APM tools are used by thousands of .NET, Java, PHP, Node.js, Python, & Ruby developers all over the world.
Explore Retrace's product features to learn more.









