
It’s five o’clock on a Friday afternoon. There are no new bug reports and everything is looking smooth. Your plan of a relaxing weekend is in sight when you get a call—the website you look after isn’t responding.
Yikes.
AWS Lambda minimizes the chance of this truly terrifying event from happening by taking care of server maintenance while you focus on coding robust applications.
AWS Lambda is a function-as-a-service platform that stores and executes your code when triggered by an Amazon Web Service (AWS) event. These events range from making an API call, to saving a file, to updating a database. You only pay for the execution of the function. There’s no other associated running costs or server maintenance, and you don’t need to worry about server load, because AWS will handle scaling. That gives you a consistent experience, no matter how much your function is used.
This post introduces AWS Lambda, discusses when you should and shouldn’t use it, and takes an in-depth look at how to create your first Ruby function using the AWS console.
At the 2014 AWS re:Invent conference, Amazon introduced Lambda to the world. Dr. Tim Wagner, general manager of AWS Lambda at the time, explained the benefits of using Lambda over EC2, the popular compute engine. Renting virtual machines in the form of EC2 instances from AWS brings flexibility and choice, but the tradeoff is that there’s an unnecessary cost when idle. Plus, there’s the additional complexity maintaining the infrastructure even when it’s not in use.
The benefits of AWS Lambda, as explained by Tim Wagner at re:Invent 2014, are
An AWS event is a JSON message containing the origin and associated event information, depending on the service. For example, if you add a file to the Amazon Simple Storage Service (S3), this will create an event containing the origin as the Simple Storage Service, the location of the file, and information that an item was added.
The services that can raise events that can trigger a function are
Events trigger a Lambda function to execute. It’s executed either directly or is added to a queue to be executed in the future. If you’d like the full list of how services create events, you can check out the AWS documentation. In short, a Lambda function subscribes to the notification-specific event from a specific source and will ignore all other events from any other source.

AWS Lambda currently supports Ruby, Java, Go, PowerShell, Node.js, C#, Ruby and Python. AWS also periodically introduces support for new programming languages
Lambda excels when the task has one or more of the following characteristics:
Lambda doesn’t excel where the task has the following characteristics:
Imagine you’re building a solution for users to store files. You choose AWS S3 as the location of your files because it’s easy to manage and scale. The users can name the images anything they want, but you want to shorten the names to fit with the user interface design of a new app.
Renaming files is an ideal task for a Lambda function because it’s a small isolated function, and it doesn’t have to be run immediately. Plus, it’s stateless.
The starting point for creating this function is a Lambda concept known as a handler. A handler is a method written in a Ruby file. In Ruby, file names are normally all lower case and separated by an underscore. For this example, we’ll use the default file name when creating a new Lambda, lambda_function.rb.
The lambda_function.rb file contains a method, and its default name is lambda_handler. This method contains the logic, and it will be run on an event trigger.
The first named argument for the lambda_handler method is the event. The JSON AWS event converts into a Ruby object and is assigned to this argument.
The second method argument is the context. The context is assigned to a hash, which contains methods that provide information about the function, such as the name and any limits. A full list of all the information context holds can be found in the AWS docs.
This code shows my lambda_function.rb file and the method, lambda_handler.
#lambda_function.rb def lambda_handler(event:, context:) end
This the base of a Lambda function and the minimum required for the Lambda to execute.
The main method that handles the processing of our event, named lambda_handler above, accepts event as an argument. This parameter is a Ruby hash converted from a JSON string containing the origin of the event and any contextual information. For our example, this will contain the name of the bucket and key of the file stored in S3.
The bucket name and key in S3 uniquely reference the image we’re storing. To retrieve these values from the event hash, update the lambda_handler method to reference the bucket name and key values from the event. See the code below for how this looks in the lambda_handler function:
def lambda_handler(event:, context:)
first_record = event["Records"].first
bucket_name = first_record["s3"]["bucket"]["name"]
file_name= first_record["s3"]["object"]["key"]
end
The above code shows retrieving the first record of the event. There will only be one record in total when adding a file to an S3 bucket. The bucket_name and file_name are then extracted from the record.
To shorten the name of the file, we’ll use standard Ruby libraries to extract the first 21 characters of the original file name.
One of the great aspects of using Ruby for writing Lambda functions is the simplicity of string manipulation. The below code will assign the first 21 characters of the variable file_name to the variable short_name:
short_name = file_name[0..20]
This code uses the fact that a string can be accessed the same way as arrays and selects the range from zero to 20.
Lambda functions are already configured to use the AWS SDK for Ruby, so no gems need to be installed before we can use the library. To reference the SDK, add a require statement to the top of your lambda_function.rb file. The below code shows the require statement at the top of the lambda_function.rb file:
require "aws-sdk-s3"
The code above loads the gem containing helper functions to communicate with the S3 service.
To move your files from one bucket to another, reference the original image and call the move_to function on that object. The code below shows how to use the built-in SDK functions to move the file:
# Get reference to the file in S3 client = Aws::S3::Client.new(region: 'eu-west-1') s3 = Aws::S3::Resource.new(client: client) object = s3.bucket(bucket_name).object(file_name) # Move the file to a new bucket object.move_to(bucket: 'upload-image-short-name', key: short_name)
This code will create a new client in the eu-west-1 region, create a new s3 resource, and use the resource to reference a specific object: in this case, a file. The next action is to move the object to a new location. The move_to method calls the S3 service to copy the original file to the new location. Then, it deletes the original.
When put together, the above code will achieve our goal of moving a file from one bucket to another, shortening the name to 21 characters.
require "aws-sdk-s3"
def lambda_handler(event:, context:)
# Get the record
first_record = event["Records"].first
bucket_name = first_record["s3"]["bucket"]["name"]
file_name = first_record["s3"]["object"]["key"]
# shorten the name
short_name = file_name[0..20]
# Get reference to the file in S3
client = Aws::S3::Client.new(region: 'eu-west-1')
s3 = Aws::S3::Resource.new(client: client)
object = s3.bucket(bucket_name).object(file_name)
# Move the file to a new bucket
object.move_to(bucket: 'upload-image-short-name', key: short_name)
end
This a working Lambda function containing the code from the previous sections of this post.
Now that we have our function, we can configure AWS to run it in a Lambda when we upload a file. To achieve this we need
If you don’t already have an AWS account, you’ll need to set one up with Amazon. They have a generous free tier, which will cover creating this function and testing it. Amazon has a great guide on how to create and activate an AWS account, so follow this guide if you don’t already have one.
Create two buckets: one that will allow initial upload of the files and another to store the files once they have been renamed. Amazon has a great guide on how to create a bucket, if you wind up needing help.

You can create a function by writing the code directly into the AWS console or by writing the code on your computer and then uploading to AWS. The rest of this post covers creating your function via the AWS console.
It’s important to note that functions are located in a specific region. A region relates to a specific datacenter owned and ran by AWS. Services can’t communicate between regions easily, so make sure the Lambda is in the same region as the S3 buckets.
If you’re choosing a region for the first time, choose the region closest to you. You should also consider that some regions don’t have all the features that others do. Concurrency Labs has a great blog post called “Save yourself a lot of pain (and money) by choosing your AWS Region wisely,” and it’ll help you choose.
To create a Lambda function through the AWS console, navigate to https://console.aws.amazon.com/lambda in your browser. By default, this will open the console in your default region. My default region is eu-west-2, located in the nearest location to me, London.
Select Create function to create a new Ruby function in the eu-west-2 region.
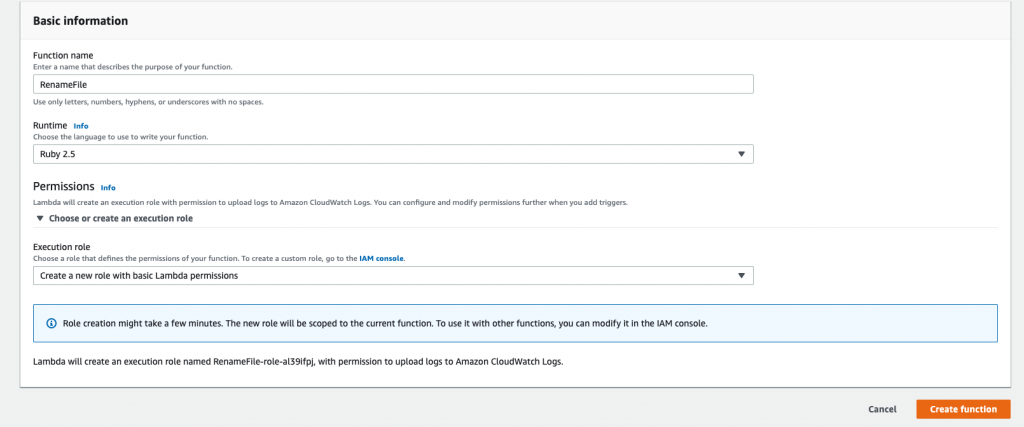
The above image shows the values you should select to create a new Ruby function successfully. Once you have selected these values, click Create function. This will display the designer view shown below:
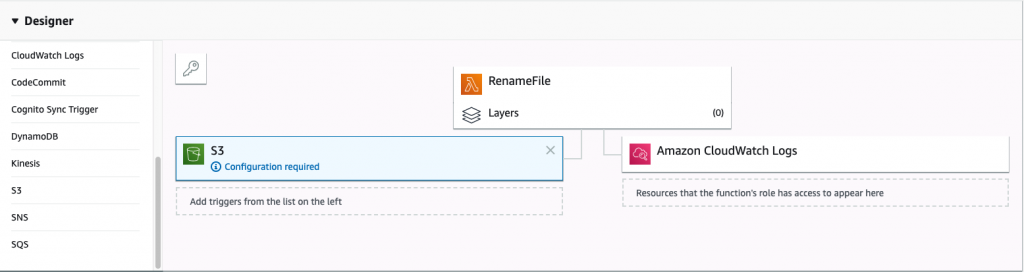
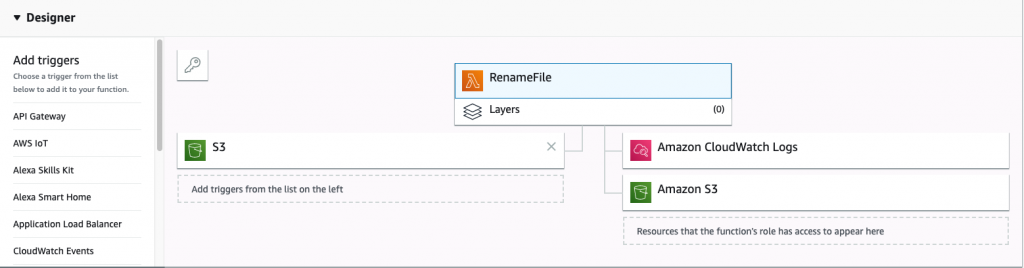
This is a visual representation of your Lambda workflow. On the left is the trigger and on the right is the flow from the trigger to the output of the function.
To set up a trigger for your Lambda function, select S3 from the designer view. This will open the configuration menu for the S3 trigger, as shown below:
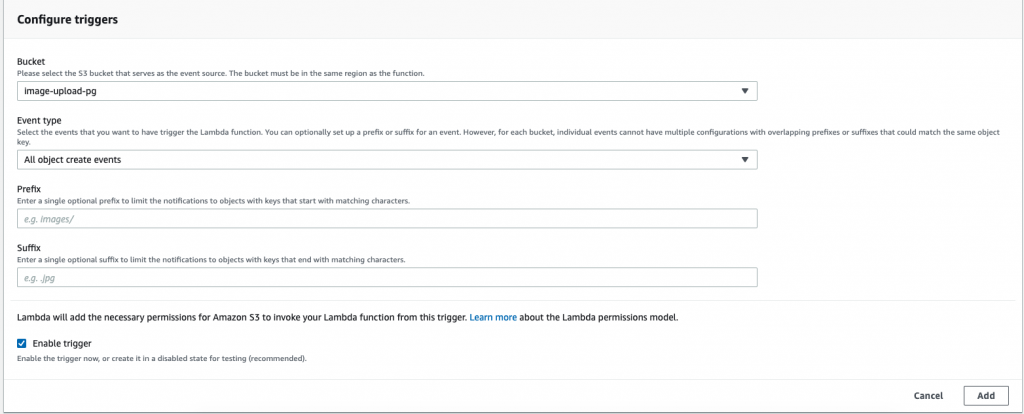
The above trigger view shows the configuration options for S3. Select the bucket that contains the uploaded images in the Bucketdropdown and press Add. Your Lambda function will now run whenever an image is uploaded to that bucket.
Select the Lambda function box from the designer view. This will open the Function code view, shown below the designer, already populated with an example function. Copy the code we created earlier in this blog post into the lambda_handler method in the lambda_function.rb file:
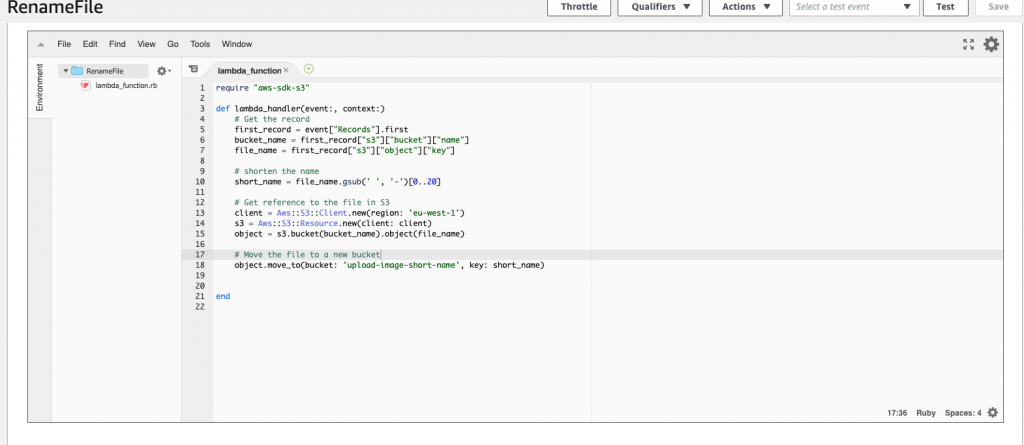
To allow your function to copy the file from one bucket to another the function requires some extra privileges. Select the Lambda function and scroll down to the configuration section shown below:
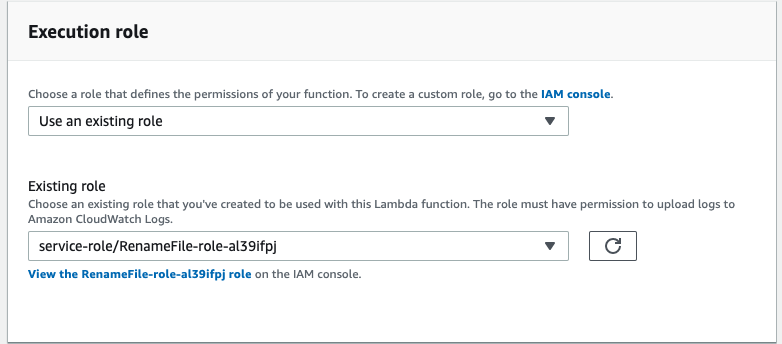
The above image shows the Lambda configuration section, focused on Execution role. Click the link named View the RenameFile-role-<unique value>. The link will redirect you to the AWS IAM service. Click Attach policy.
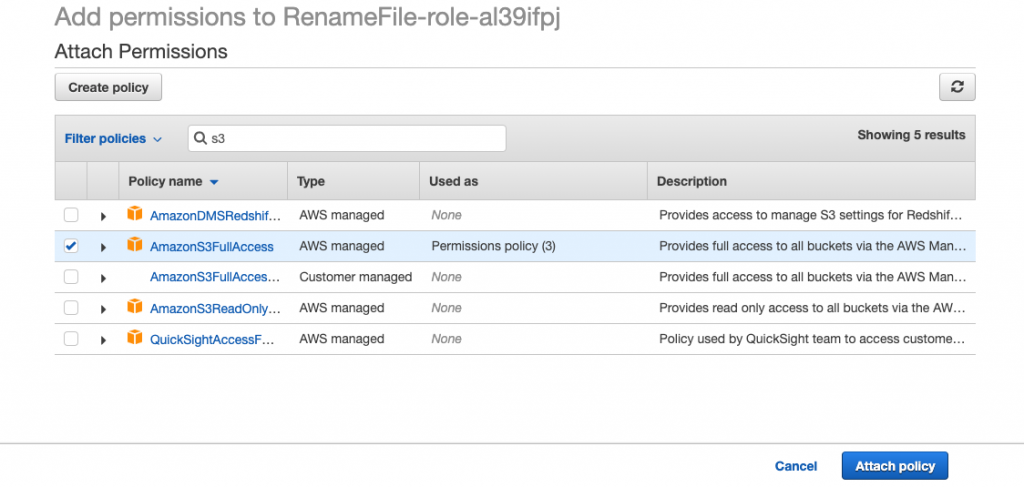
The above shows the attach policy view of the IAM service.
Now, search for s3. This will show all the policies relevant to S3. Select AmazonS3FullAccess and press the Attach policy button. You should now see an extra box on the designer view, and Lambda will now have access to all buckets in S3.
Upload a file with a name longer than 21 characters to your image bucket. The file will shortly be deleted and transferred to the small names bucket and be 21 characters long. And there you go—test passed!
Ruby is a great language, and I’m really happy AWS is now supporting Ruby functions in Lambda. Once you’re comfortable with the basics and want more advanced functions, Serverless Framework is a great next step. Serverless Framework allows you to package up gems to use in your function outside of those provided by Lambda. It also helps with versioning and organizing your code, along with storing the configuration for your functions.
Another tool that could speed up your development is Ruby on Jets, an easy-to-use Rails-like framework to create API endpoints and recurring jobs. These tools provide an abstraction on top of Lambda, and the generated functions can always be verified via the AWS console.
CloudWatch is the default monitoring tool created by AWS to keep track of errors in your Lambda functions. It’s a good tool, but it’s very labor intensive because looking through the CloudWatch logs is a manual process. Using a tool like Retrace could help monitor how and when each of your functions are being executed and track any errors together with context in a convenient dashboard.
Lambda is not the solution to every problem, and overuse might lead to unnecessary complexity. Take each use case one at a time and decide if Lambda is the correct solution for you.
Stackify's APM tools are used by thousands of .NET, Java, PHP, Node.js, Python, & Ruby developers all over the world.
Explore Retrace's product features to learn more.









