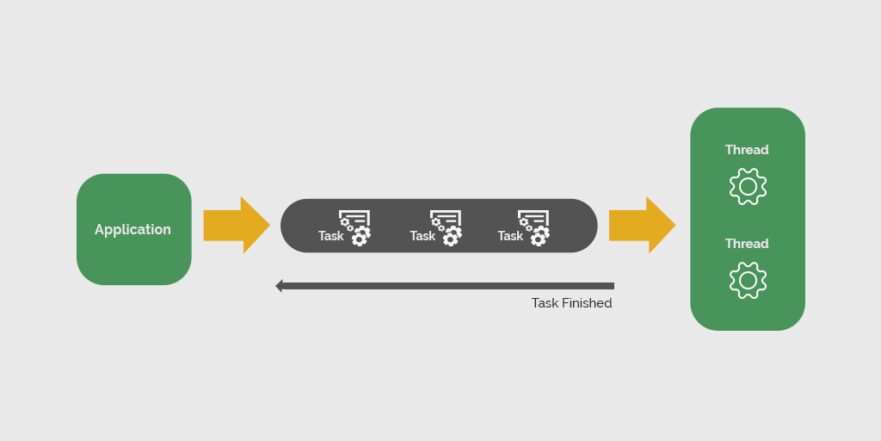
Thread pool is a core concept in multithreaded programming which, simply put, represents a collection of idle threads that can be used to execute tasks.
First, let’s outline a frame of reference for multithreading and why we may need to use a thread pool.
A thread is an execution context that can run a set of instructions within a process – aka a running program. Multithreaded programming refers to using threads to execute multiple tasks concurrently. Of course, this paradigm is well supported on the JVM.
Although this brings several advantages, primarily regarding the performance of a program, the multithreaded programming can also have disadvantages – such as increased complexity of the code, concurrency issues, unexpected results and adding the overhead of thread creation.
In this article, we’re going to take a closer look at how the latter issue can be mitigated by using thread pools in Java.
Creating and starting a thread can be an expensive process. By repeating this process every time we need to execute a task, we’re incurring a significant performance cost – which is exactly what we were attempting to improve by using threads.
For a better understanding of the cost of creating and starting a thread, let’s see what the JVM actually does behind the scenes:
Of course, the details of all this will depend on the JMV and the operating system.
In addition, more threads mean more work for the system scheduler to decide which thread gets access to resources next.
A thread pool helps mitigate the issue of performance by reducing the number of threads needed and managing their lifecycle.
Essentially, threads are kept in the thread pool until they’re needed, after which they execute the task and return the pool to be reused later. This mechanism is especially helpful in systems that execute a large number of small tasks.
Java provides its own implementations of the thread pool pattern, through objects called executors. These can be used through executor interfaces or directly through thread pool implementations – which does allow for finer-grained control.
The java.util.concurrent package contains the following interfaces:
Alongside these interfaces, the package also provides the Executors helper class for obtaining executor instances, as well as implementations for these interfaces.
Generally, a Java thread pool is composed of:
In the following sections, let’s see how the Java classes and interfaces that provide support for thread pools work in more detail.
The Executors class contains factory methods for creating different types of thread pools, while Executor is the simplest thread pool interface, with a single execute() method.
Let’s use these two classes in conjunction with an example that creates a single-thread pool, then uses it to execute a simple statement:
Executor executor = Executors.newSingleThreadExecutor();
executor.execute(() -> System.out.println("Single thread pool test"));
Notice how the statement can be written as a lambda expression – which is inferred to be of Runnable type.
The execute() method runs the statement if a worker thread is available, or places the Runnable task in a queue to wait for a thread to become available.
Basically, the executor replaces the explicit creation and management of a thread.
The factory methods in the Executors class can create several types of thread pools:
Next, let’s take a look into what additional capabilities the ExecutorService interface.
One way to create an ExecutorService is to use the factory methods from the Executors class:
ExecutorService executor = Executors.newFixedThreadPool(10);
Besides the execute() method, this interface also defines a similar submit() method that can return a Future object:
Callable<Double> callableTask = () -> {
return employeeService.calculateBonus(employee);
};
Future<Double> future = executor.submit(callableTask);
// execute other operations
try {
if (future.isDone()) {
double result = future.get();
}
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
As you can see in the example above, the Future interface can return the result of a task for Callable objects, and can also show the status of a task execution.
The ExecutorService is not automatically destroyed when there are no tasks waiting to be executed, so to shut it down explicitly, you can use the shutdown() or shutdownNow() APIs:
executor.shutdown();
This is a subinterface of ExecutorService – which adds methods for scheduling tasks:
ScheduledExecutorService executor = Executors.newScheduledThreadPool(10);
The schedule() method specifies a task to be executed, a delay value and a TimeUnit for the value:
Future<Double> future = executor.schedule(callableTask, 2, TimeUnit.MILLISECONDS);
Furthermore, the interface defines two additional methods:
executor.scheduleAtFixedRate(
() -> System.out.println("Fixed Rate Scheduled"), 2, 2000, TimeUnit.MILLISECONDS);
executor.scheduleWithFixedDelay(
() -> System.out.println("Fixed Delay Scheduled"), 2, 2000, TimeUnit.MILLISECONDS);
The scheduleAtFixedRate() method executes the task after 2 ms delay, then repeats it at every 2 seconds. Similarly, the scheduleWithFixedDelay() method starts the first execution after 2 ms, then repeats the task 2 seconds after the previous execution ends.
In the following sections, let’s also go through two implementations of the ExecutorService interface: ThreadPoolExecutor and ForkJoinPool.
This thread pool implementation adds the ability to configure parameters, as well as extensibility hooks. The most convenient way to create a ThreadPoolExecutor object is by using the Executors factory methods:
ThreadPoolExecutor executor = (ThreadPoolExecutor) Executors.newFixedThreadPool(10);
In this manner, the thread pool is preconfigured for the most common cases. The number of threads can be controlled by setting the parameters:
Digging a bit further, here’s how these parameters are used.
If a task is submitted and fewer than corePoolSize threads are in execution, then a new thread is created. The same thing happens if there are more than corePoolSize but less than maximumPoolSize threads running, and the task queue is full. If there are more than corePoolSize threads which have been idle for longer than keepAliveTime, they will be terminated.
In the example above, the newFixedThreadPool() method creates a thread pool with corePoolSize=maximumPoolSize=10, and a keepAliveTime of 0 seconds.
If you use the newCachedThreadPool() method instead, this will create a thread pool with a maximumPoolSize of Integer.MAX_VALUE and a keepAliveTime of 60 seconds:
ThreadPoolExecutor cachedPoolExecutor = (ThreadPoolExecutor) Executors.newCachedThreadPool();
The parameters can also be set through a constructor or through setter methods:
ThreadPoolExecutor executor = new ThreadPoolExecutor( 4, 6, 60, TimeUnit.SECONDS, new LinkedBlockingQueue<Runnable>() ); executor.setMaximumPoolSize(8);
A subclass of ThreadPoolExecutor is the ScheduledThreadPoolExecutor class, which implements the ScheduledExecutorService interface. You can create this type of thread pool by using the newScheduledThreadPool() factory method:
ScheduledThreadPoolExecutor executor = (ScheduledThreadPoolExecutor) Executors.newScheduledThreadPool(5);
This creates a thread pool with a corePoolSize of 5, an unbounded maximumPoolSize and a keepAliveTime of 0 seconds.
Another implementation of a thread pool is the ForkJoinPool class. This implements the ExecutorService interface and represents the central component of the fork/join framework introduced in Java 7.
The fork/join framework is based on a “work-stealing algorithm”. In simple terms, what this means is that threads that run out of tasks can “steal” work from other busy threads.
A ForkJoinPool is well suited for cases when most tasks create other subtasks or when many small tasks are added to the pool from external clients.
The workflow for using this thread pool typically looks something like this:
To create a ForkJoinTask, you can choose one of its more commonly used subclasses, RecursiveAction or RecursiveTask – if you need to return a result.
Let’s implement an example of a class that extends RecursiveTask and calculates the factorial of a number by splitting it into subtasks depending on a THRESHOLD value:
public class FactorialTask extends RecursiveTask<BigInteger> {
private int start = 1;
private int n;
private static final int THRESHOLD = 20;
// standard constructors
@Override
protected BigInteger compute() {
if ((n - start) >= THRESHOLD) {
return ForkJoinTask.invokeAll(createSubtasks())
.stream()
.map(ForkJoinTask::join)
.reduce(BigInteger.ONE, BigInteger::multiply);
} else {
return calculate(start, n);
}
}
}
The main method that this class needs to implement is the overridden compute() method, which joins the result of each subtask.
The actual splitting is done in the createSubtasks() method:
private Collection<FactorialTask> createSubtasks() {
List<FactorialTask> dividedTasks = new ArrayList<>();
int mid = (start + n) / 2;
dividedTasks.add(new FactorialTask(start, mid));
dividedTasks.add(new FactorialTask(mid + 1, n));
return dividedTasks;
}
Finally, the calculate() method contains the multiplication of values in a range:
private BigInteger calculate(int start, int n) {
return IntStream.rangeClosed(start, n)
.mapToObj(BigInteger::valueOf)
.reduce(BigInteger.ONE, BigInteger::multiply);
}
Next, tasks can be added to a thread pool:
ForkJoinPool pool = ForkJoinPool.commonPool(); BigInteger result = pool.invoke(new FactorialTask(100));
At first look, it seems that the fork/join framework brings improved performance. However, this may not always be the case depending on the type of problem you need to solve.
When choosing a thread pool, it’s important to also remember there is overhead caused by creating and managing threads and switching execution from one thread to another.
The ThreadPoolExecutor provides more control over the number of threads and the tasks that are executed by each thread. This makes it more suitable for cases when you have a smaller number of larger tasks that are executed on their own threads.
By comparison, the ForkJoinPool is based on threads “stealing” tasks from other threads. Because of this, it is best used to speed up work in cases when tasks can be broken up into smaller tasks.
To implement the work-stealing algorithm, the fork/join framework uses two types of queues:
When threads run out of tasks in their own queues, they attempt to take tasks from the other queues. To make the process more efficient, the thread queue uses a deque (double ended queue) data structure, with threads being added at one end and “stolen” from the other end.
Here is a good visual representation of this process from The H Developer:
In contrast with this model, the ThreadPoolExecutor uses only one central queue.
One last thing to remember is that the choosing a ForkJoinPool is only useful if the tasks create subtasks. Otherwise, it will function the same as a ThreadPoolExecutor, but with extra overhead.
Now that we have a good foundational understanding of the Java thread pool ecosystem let’s take a closer look at what happens during the execution of an application that uses a thread pool.
By adding some logging statements in the constructor of FactorialTask and the calculate() method, you can follow the invocation sequence:
13:07:33.123 [main] INFO ROOT - New FactorialTask Created 13:07:33.123 [main] INFO ROOT - New FactorialTask Created 13:07:33.123 [main] INFO ROOT - New FactorialTask Created 13:07:33.123 [main] INFO ROOT - New FactorialTask Created 13:07:33.123 [ForkJoinPool.commonPool-worker-1] INFO ROOT - New FactorialTask Created 13:07:33.123 [ForkJoinPool.commonPool-worker-1] INFO ROOT - New FactorialTask Created 13:07:33.123 [main] INFO ROOT - New FactorialTask Created 13:07:33.123 [main] INFO ROOT - New FactorialTask Created 13:07:33.123 [main] INFO ROOT - Calculate factorial from 1 to 13 13:07:33.123 [ForkJoinPool.commonPool-worker-1] INFO ROOT - New FactorialTask Created 13:07:33.123 [ForkJoinPool.commonPool-worker-2] INFO ROOT - New FactorialTask Created 13:07:33.123 [ForkJoinPool.commonPool-worker-1] INFO ROOT - New FactorialTask Created 13:07:33.123 [ForkJoinPool.commonPool-worker-2] INFO ROOT - New FactorialTask Created 13:07:33.123 [ForkJoinPool.commonPool-worker-1] INFO ROOT - Calculate factorial from 51 to 63 13:07:33.123 [ForkJoinPool.commonPool-worker-2] INFO ROOT - Calculate factorial from 76 to 88 13:07:33.123 [ForkJoinPool.commonPool-worker-3] INFO ROOT - Calculate factorial from 64 to 75 13:07:33.163 [ForkJoinPool.commonPool-worker-3] INFO ROOT - New FactorialTask Created 13:07:33.163 [main] INFO ROOT - Calculate factorial from 14 to 25 13:07:33.163 [ForkJoinPool.commonPool-worker-3] INFO ROOT - New FactorialTask Created 13:07:33.163 [ForkJoinPool.commonPool-worker-2] INFO ROOT - Calculate factorial from 89 to 100 13:07:33.163 [ForkJoinPool.commonPool-worker-3] INFO ROOT - Calculate factorial from 26 to 38 13:07:33.163 [ForkJoinPool.commonPool-worker-3] INFO ROOT - Calculate factorial from 39 to 50
Here you can see there are several tasks created, but only 3 worker threads – so these get picked up by the available threads in the pool.
Also notice how the objects themselves are actually created in the main thread, before being passed to the pool for execution.
This is actually a great way to explore and understand thread pools at runtime, with the help of a solid logging visualization tool such as Prefix.
The core aspect of logging from a thread pool is to make sure the thread name is easily identifiable in the log message; Log4J2 is a great way to do that by making good use of layouts for example.
Although thread pools provide significant advantages, you can also encounter several problems while using one, such as:
To mitigate these risks, you have to choose the thread pool type and parameters carefully, according to the tasks that they will handle. Stress-testing your system is also well-worth it to get some real-world data of how your thread pool behaves under load.
Thread pools provide a significant advantage by, simply put, separating the execution of tasks from the creation and management of threads. Additionally, when used right, they can greatly improve the performance of your application.
And, the great thing about the Java ecosystem is that you have access to some of the most mature and battle-tested implementations of thread-pools out there if you learn to leverage them properly and take full advantage of them.
Want to improve your Java applications? Try Stackify Retrace for application performance and troubleshooting and Stackify Prefix to write better code.
Stackify's APM tools are used by thousands of .NET, Java, PHP, Node.js, Python, & Ruby developers all over the world.
Explore Retrace's product features to learn more.









