We’re on the verge of something here, people.
A growing number of companies are shipping software in minutes.
Yeah, you read that right. Minutes. Not hours, not weeks, months, or longer. Minutes.
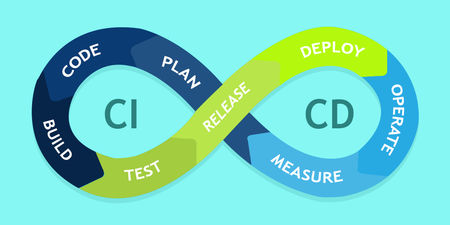
Often, teams struggle to ship software into the customer’s hands due to lack of consistency and excessive manual labor. Continuous integration (CI) and continuous delivery (CD) deliver software to a production environment with speed, safety, and reliability.
In today’s post, I’ll introduce these concepts, show you how to get it right, and identify what’s important. Then, I’ll include a list of tools commonly used to implement CICD. When you finish reading, you’ll have a better understanding not only of all the benefits that these practices bring, but also the challenges you might encounter.
Simple enough?
Let’s talk CICD.
With continuous integration (CI), a developer practices integrating the code changes continuously with the rest of the team. The integration happens after a “git push,” usually to a main branch—more on this later. Then, on a dedicated server, an automated process builds the application and runs a set of tests to confirm that the newest code integrates with what’s currently in the main branch.

If you’re doing CI and for some reason the integration fails, that means the broken build becomes the highest priority to fix before continuing to add more features. System quality—not just velocity—is important. CI works in three simple stages: push, test, and fix.
This CI practice is about pushing code into the main branch, because that’s the branch that’s going to be used to release software.
When you practice CI, it doesn’t mean you’ll no longer use branches. You still will. The only difference is that because you amplify feedback when you integrate code continually, branches become temporary. A branch might live only for the day; then it’s integrated into the main branch.
But what about incomplete changes? Well, you can integrate incomplete changes by using feature flags.
Feature flags are an if condition determining whether to run the new code or not. If a change isn’t complete yet, the flag is off by default. That way, when you integrate the code, the rest of the team has a chance to review it. The same technique applies if the new code has bugs.

To validate each time a developer integrates new code, CI relies on an automated and reliable suite of tests.
Include as many tests as possible, but also keep the CI loop as short as possible. You might have to lean heavily on unit testing and lightly on integration testing.
Lastly, when you spot a bug in production, create a test case and include it in the CI loop. You can easily confirm that it’s reliable: If the flag for the bug fix is off and the build breaks; if the flag for the bug fix is on, the build works.
When the build is broken, fixing it should be the priority for the team. Every time a build is broken, no one else can continue pushing code changes. Everyone on the team is aware of the issues happening.
Besides, whoever breaks the build will try to fix the problem, and if help is needed, then the rest of the team is there. In software, if the build can’t be fixed within minutes, the team should decide if they’ll remove the code or turn the feature flag off. Having a “green” build is not one person’s problem anymore.
Let me use the definition for continuous delivery (CD) from Jez Humble’s site:
Continuous Delivery is the ability to get changes of all types—including new features, configuration changes, bug fixes and experiments—into production, or into the hands of users, safely and quickly in a sustainable way. We achieve all this by ensuring our code is always in a deployable state, even in the face of teams of thousands of developers making changes on a daily basis.
CI’s mission is then to move those artifacts throughout all the different environments of an organization’s development life cycle. What’s critical in CD is that it’ll always deploy the same artifact in all environments. Therefore, a build in CI happens only once and not for each environment. The artifact produced will work with placeholders or environment variables for the build-once approach to work.

The following are the vital principles for continuous delivery. When you put them into practice, they’ll help you to deliver software safely and quickly in a sustainable way, as per the CD definition I included above.
Usually, every time a deployment happens, the application’s stability is at risk. Therefore, we tend to distance deployments from each other. But the problem with that approach is that we end up accumulating many changes. Chances are that one of those changes might have problems, forcing us to roll back the other changes that were working. Been there, done that.
What CD fosters—with the combination of CI, which implies quality is built in—is that we should work in small batches.
Machines are perfect candidates for repetitive tasks. Automation is a critical principle in CD because it helps to increase the sustainability of the process.
Be cautious, though. Once you introduce automation, you still need people’s minds to improve the process. You can achieve automation with the help of practices like infrastructure-as-code, pipeline-as-code, or configuration management.
CD will help to produce one-click deployments that can be triggered on demand.
Are you currently compiling the application from a developer’s machine? Start by using a dedicated server for CI, and build the application in a different server. Are you manually copying and pasting application artifacts? Start by automating the copying/pasting process. It doesn’t matter if you’ve added small improvements or if you’re happy with how advanced the process is. There’s always going to be something to improve. CD doesn’t have an end date.
CD produces happier teams because now the deployment pipeline isn’t just an operations problem. Operations will seek ways to help developers build software with quality. And they’ll do it not just by coaching, but also by providing all the necessary tools that a developer might need to understand problems better. A team won’t optimize the process just for them, but it will add improvements that help the organization deliver more value to customers. That’s instead of the traditional approach of rewarding developers for how fast they ship, or rewarding operations for how reliable the system is. If that’s what you’re doing, these two teams will have different goals, and that won’t work.
Everyone in the team is responsible for creating a safer, quicker, and deterministic delivery pipeline continuously.
We’ve already covered a bit about the benefits of CI/CD throughout the post, but I figured it’d make sense to list the main ones in a dedicated section.
Without further ado, here’s a non-exhaustive list of CI/CD benefits:
CI/CD is mainly a cultural shift, but tools can help. Here’s a list of common tools that you can start using today.
This list fails to capture how many tools are actually out there. But the purpose is only to give you a few options. You can use whatever tool works best for you.
Next, let me try to assemble all of the concepts I’ve discussed in this post with a traditional but straightforward workflow for a CI/CD pipeline using a Microsoft stack. Each piece can be interchangeable with other tools, platforms, and languages.
What’s important is the workflow, which you can see illustrated here. You’ll definitely want to take a look at the illustration so the summary below makes sense.
In summary, here’s what it shows:
When a release to another environment like test or production happens, steps 1-4 won’t need to be run again.
As you’ve seen, CI/CD brings many benefits to the table—once you get it right. It’d be disingenuous of my part, though, if I said adopting CI/CD is a walk in the park. It’s not.
And that’s especially true if it’s your first attempt. There are obstacles you might face, and there are significant errors you must avoid. So, before wrapping up, let’s cover some implementation challenges and common errors in implementing these great practices.
One of the most important implementation challenges for CI/CD is cultural resistance. As you’ve read multiple times during the post, adopting CI/CD is not only about tools and procedures, but about a cultural shift. You might face resistance from people within your organization that resist change on the basis of “this is the way we’ve always done it.” A suggestion here is to invest in education, training people on the benefits of CI/CD. Even consider workshops, so folks can get a first contact with CI/CD and see that it isn’t rocket science.
Another important challenge that you can also solve with education is a lack in skills for CI/CD. The skill gap can certainly pose a challenge, particularly in the first stages, but there’s really not much you can do besides investing in training for employees.
A final challenge would be analysis paralysis when selecting tools. The sheer number of tools available for CI/CD makes picking one somewhat of a daunting task. Fortunately, there are many, many tools you can use for free, so I’d suggest starting with one of those to learn and implement a minimum viable setup, and then considering other options.
An important common mistake when starting to implement CI/CD is to go for an extremely complicated setup without the need for it. An overly complicated configuration will slow down your pipeline, discouraging people from pushing often to the main branch, which is the very opposite of what you want to accomplish!
Also, not taking enough care of your test suite. The test suite is the heart of your CI/CD ecosystem: ensure it has a good coverage of your application, that it’s reliable, easily maintainable, and runs fast.
Finally, a serious mistake when implementing CI/CD is failing to take database migrations into account. Database migrations are always a pain point in deployments; a failed migration can result in outages and data loss, generating financial and reputational damage for the company. The recommendation here is also education: research about how to handle database migrations in CI/CD in a safe, reliable, and reversible way, without causing downtime and loss of data.
CI/CD helps teams to be more productive when shipping software with quality built in. But the road to having one-click deployments that you can produce on demand is not an easy one. That’s mainly because even though there are powerful tools that will help you to achieve CI/CD more effectively, CI/CD requires a cultural change: a mindset that every person in the team needs to understand very well.

I’d recommend that you continue learning with books like Continuous Delivery from Jez Humble. Try to focus more on how to adopt the principles and practices of CI/CD, rather than how or which tools to use. Lastly, CI/CD implementation doesn’t have an end date, like a project, where once you’re at a certain stage you can forget about it. It has to improve continuously. Platforms like Retrace that give you centralized logging and error tracking will help you to improve continuously based on the feedback you receive after each release to production.
Try Stackify’s free code profiler, Prefix, to write better code on your workstation. Prefix works with .NET, Java, PHP, Node.js, Ruby, and Python.

Stackify's APM tools are used by thousands of .NET, Java, PHP, Node.js, Python, & Ruby developers all over the world.
Explore Retrace's product features to learn more.










{kind=link}