
We talked a bit about the Software Development Life Cycle (SDLC) in a recent post, but today, we’re going to dig a little deeper into one particular and crucial element in the testing phase, particularly for Agile development: regression testing.
Software testers perform regression testing on a changed or updated computer program to ensure that older software features – which they previously developed and tested – still perform exactly as they did before. One way to think about software regression is to think about somebody who implements a new air conditioning system in their home only to find that while their new air conditioning system works as expected, the lights no longer work.
Regression testing will often involve running existing tests against the modified code to make sure that the new code did not break anything that worked before the update. Regression testing can eliminate much of the risk associated with software updates. In addition to running existing tests, testers might tweak existing tests by introducing different secondary conditions as variables.

With the increased popularity of the Agile development methodology, regression testing has taken on added importance. Many companies today adopt an iterative, Agile approach to software development. For example, the great many software as a service (SaaS) providers will regularly update their features or add new functionality to their offerings with each software update. To ensure their core product remains unaffected by new feature additions, these companies will perform regression testing.
Regression testing is a fundamental part of the software development lifecycle. ProtoTech Solutions illustrates the concept nicely with this graph:
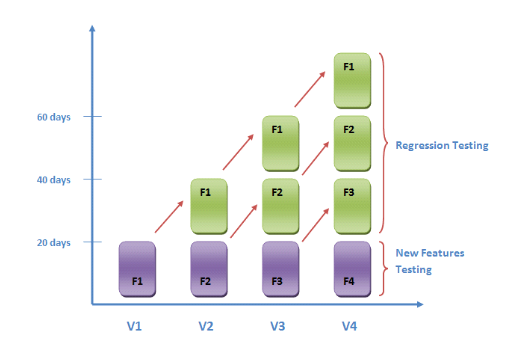
While regression testing is a vital element of the QA process, there are a number of challenges it brings.
As you and your team perform regression testing, there are some best practices to bear in mind.
A regression pack is a collection of test cases that are performed as each new software update is completed. The scripted tests included in a regression pack are created with the requirement specifications of older versions of the software in mind.
Random or ad-hoc tests may also be included in the pack. It is a good idea to keep your regression pack up to date. Regression testing can be time-consuming, the last thing you need is to include tests that check whether an older feature which has been removed is still working.
Highly-trafficked paths are the most frequent use cases for your application. They will include the basic functionality of your application and most popular features. You should know your core group of users and the typical features and interactions they are most reliant on. Your regression pack must include tests that ensure this core functionality is working as it should.
Tests that have previously identified bugs and defects are also worth including in your regression pack. Alternatively, tests that the program passes consistently are good candidates for archival.
Automated regression testing can make the process much more efficient. Running the same tests over and over again can result in testers becoming bored and losing motivation. The quality of their work might suffer as well as motivation dips. Automated regression testing can free up your testers to work on the trickier case specific tests. Automation software can handle the more tedious tests. Another consideration here is that testing software can be re-used so, even though there is an initial outlay, are making efficiency gains on an ongoing basis meaning your testing software will quickly demonstrate ROI.
Do not confuse regression testing with retesting. Testers perform regression testing to ensure that updated code has not caused any existing functionality to break. Retesting, on the other hand, refers to tests that are performed when a test case has identified some defects. Once testers fix the defects, they perform the tests again to ensure they have resolved the issues.
Prioritize retesting over regression testing because testers have already identified issues. Testers use regression testing to identify potential issues.
Because regression testing can involve varying types of tests, there’s no single, clear-cut method for performing a “regression test,” per say. However, there are plenty of valuable insights and informative tutorials for incorporating regression testing practices into your overall SDLC. Check out the following tutorials and guides for more insights on selecting test cases, creating and executing a regression testing plan, best practices, and more:
After reading this post, you now know what regression testing is. GUI regression testing is just what it sounds like: regression testing executed through the GUI (Graphical User Interface). In other words, it is testing aimed at finding software regressions by interacting with the application through its user interface, in a way as close as possible to how a real user would use the system.
Testers carry out this form of testing mostly manually because automating it is hard. Tests that exercise the GUI are usually hard to write, slow to execute and very fragile, because even small changes to the UI—such as changing ids or CSS classes tend to break them.
Change Impact Analysis identifies the parts of the application affected by a given change. That way, it’s possible to focus your efforts only on the modules that changed, significantly reducing the amount of effort needed to carry out regression testing.
Lack of revision control hygiene can be a factor in causing known programming issues to re-emerge. For instance, if a team doesn’t use proper CI/CD and its members take a long time to integrate their code after working in isolation, that could lead to complex merging conflicts. In an attempt to solve such conflicts, a developer could inadvertently override a fix made by a colleague, causing a bug to reappear.
Fragile fixes—i.e. fixes made without a proper quality control and end-up creating other issues—cause waste of time and money, besides reputational loss. They are the cause of regressions that upset users and taint the company’s reputation, not to mention the monetary cost of having to fix features that were already working perfectly.
The timing of regression testing is based on several factors, such as its size and nature, whether it employs agile methodologies, and the degree of software testing automation.
In general, testers should perform regression testing just before any (major) releases, once they have completed the coding for that particular release. Since regression testing is complex and can take time, it makes sense to implement a coding freeze once testing begins.

It’s time for me to walk you through a simple example of what a regression testing session might look like in real life.
Let’s imagine you built a CMS (content management system) for a news organization, that allows them to write, manage and publish news stories. At first, a given news story could belong to only one category—e.g. “sports.” But then a change in requirements came in: now the client wants to be able to associate a news story with multiple categories.
After a change impact analysis, you identify the following risk areas:
After identifying the risk areas, testers can write one or more test cases for each one. Ideally, we would already have test cases for at least some of the areas above in our regression pack. However, testers might not have covered some areas yet because they didn’t previously perceive them as critical, or possibly due to budgetary reasons. No problem: as you’ve seen, routinely updating your regression pack is a great practice, so now would be the perfect time to do it.
Here’s an example of test case for the first risk area we identified—verifying that the story registration page correctly handles multiple categories:
| STEP | EXPECTED RESULT |
| 1. Go to the CMS main page | The user is prompted for log in |
| 2. Log in as an user with the “editor” role | The user is redirected to the “Manage User Stories” page |
| 3. Click on the “Add News Story” button | The user is redirect to the “News Story Register” page |
| 4. Add a title for the story | The title is displayed as entered |
| 5. Write a small body for the story, using the rich-text editor that supports markdown | A preview for the story appears to the right of the input, as the user types |
| 6. Go to the “Categories” field. Type “Spo” and wait | The autocomplete kicks-in and suggests “Sports” |
| 7. Click on the “Sports” suggestion | “Sports” is added to the box of categories with the format of a label |
| 8. Go to the “Categories” field. Type “Mus” | “Music” is suggested by the auto-complete. |
| 9. Click on the “Music” suggestion. | “Music” is added to the box of categories in the same style as “Sports.” |
| 10. Click on “Save” | The message “News story successfully saved” appears and the user is redirected to the “Manage User Stories” page. |
The example above, despite being simple, clearly demonstrates how regression testing is crucial. Even a seemingly easy change such as allowing users to associate a news story with more than one category can have far reaching implications for the behavior of a system.
However, as we’ve explained, regression testing can be quite costly, slow, and even difficult to automate. While adopting regression testing is essential, you should also look for ways to reduce the need for regression testing. In other words, if you could preemptively find problems before they even manifest, during development, you’d greatly reduce your test burden.
And a great way to achieve the above is to leverage the solutions offered by Stackify. Stackify offers a catalogue of application performance management solutions that can help you monitor your application in real time, making your system much more reliable. Start your free trial today.
Stackify's APM tools are used by thousands of .NET, Java, PHP, Node.js, Python, & Ruby developers all over the world.
Explore Retrace's product features to learn more.









