
The last decade has ushered in a golden era of software engineering. The rise of cloud computing freed companies from managing their own data centers and provided on-demand scaling. These services allow for provisioning servers on the fly using configuration and code. Treating that task as just another type of software development led to the advent of DevOps.
Cloud computing and DevOps were the secret sauce that brought operations into the twenty-first century, much like test-driven development and agile practices did for the actual writing of code. Now all phases of the software development lifecycle, from conception to maintenance, can be treated as an agile development practice.
One of the most important changes this revolution brought about was getting past the “don’t wake the baby” syndrome. Traditional, slow-moving IT shops fell into a pattern of living in fear of breaking things. In an agile DevOps world, we move quickly and make small changes often. We’re not afraid to break things as long as we can fix them quickly.
It’s important to have metrics to tell you how you’re doing. Especially how fast you fix things. The number that tells you this is called mean time to resolution (MTTR). And an essential tool for measuring MTTR is an application performance monitoring (APM) service. Stackify’s Retrace is one such tool.
Let’s see how we can use Retrace to reduce MTTR and keep ourselves on track.

Retrace is a SaaS product, so the first thing to do is sign up for an account. There’s a free trial period, so you can set it up and thoroughly check out all the great features without shelling out any money. Be sure to grant access to your whole team. Good performance and minimal downtime are an all-hands-on-deck effort.
The next step is to hook up your application to talk to Retrace. How this works depends on what language you use and how your app is deployed. But basically, Retrace provides a lightweight plugin—called an agent—that you install on your servers.
There are also various configuration options for you to tweak. You will definitely want to make sure your application’s logs and errors are being reported to Retrace. This will let you take advantage of all the features Retrace has to offer. Stackify has very thorough documentation for Retrace available online.
Once you have your account set up and integrated with your application, you can start getting insights into how your application is performing. You can track slow code and trouble spots, keep a close eye on errors, and more. These are excellent starting points for reducing MTTR.
If your company relies on multiple applications or services, you’ll want to hook all of them up to Retrace. Then you can get a bird’s-eye view of how these apps are doing.
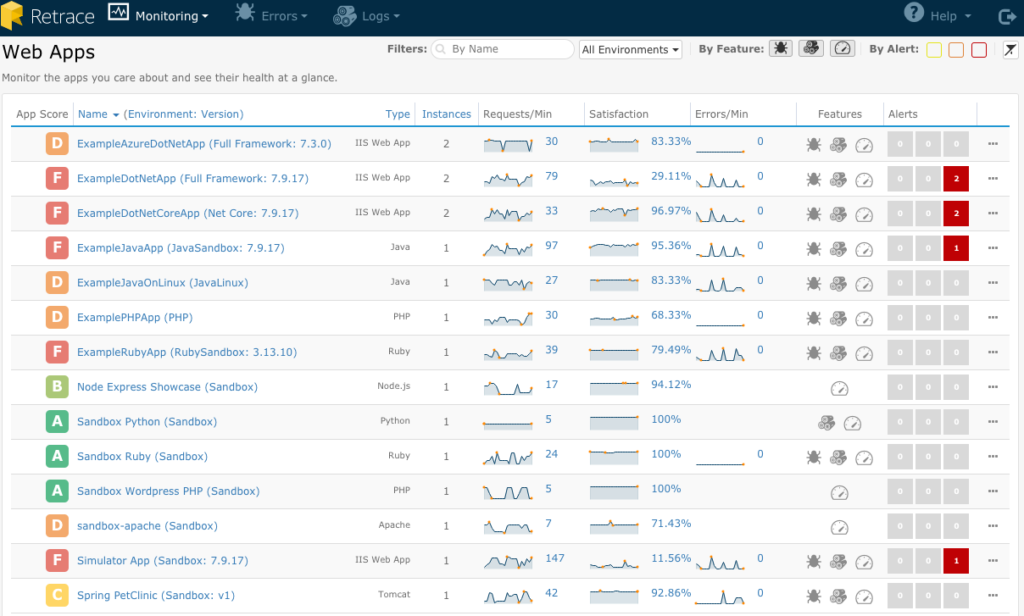
This Web Apps page provides a sortable list of all the apps monitored by Retrace. The columns tell you things like the overall app score, the number of requests per minute the app is serving, how many errors it is throwing, and if there are any new alerts for the app.
All of these stats will help you reduce MTTR. If an app has a poor score or new alerts, you should dig in immediately. An increase in the number of errors will also tell you something is wrong. And a decrease in the number of requests per minute could be a sign of trouble. Both of those situations and more can be configured to trigger alerts.
From the overview of all apps, you can drill down into a specific app that is having problems. The app dashboard page has several tabs across the top, each of which provides a wealth of information about this specific app.
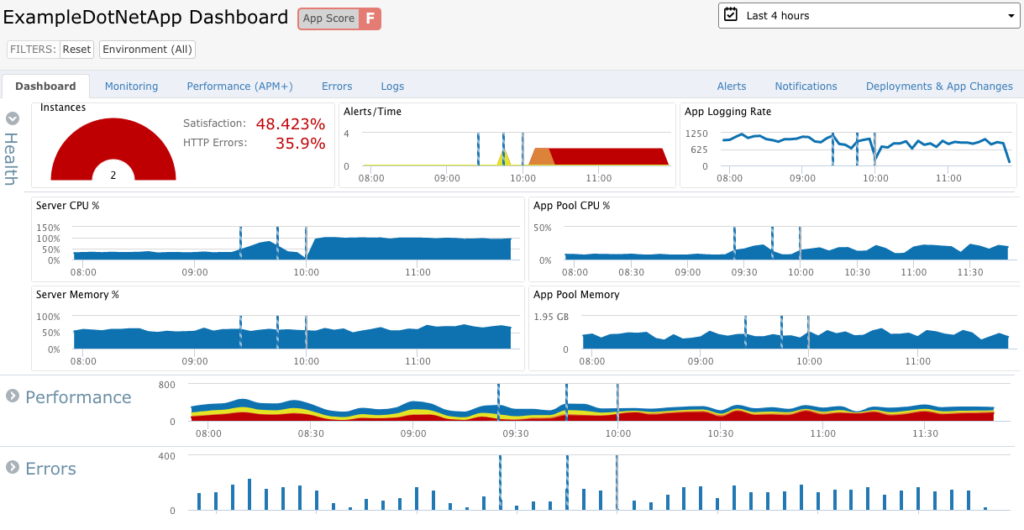
The dashboard tab packs in a lot of data. Note that you can open and close each of the sections on this page: health, performance, and errors. This makes it easy to hide the details if they’re not relevant to your problem.
Also, note that these graphs provide more information when you hover over them. This helps you track down issues more quickly. And quicker resolution means reduced MTTR!
The performance (APM+) tab of the app dashboard gives you even more detail about how your app is doing. Here you have graphs of the top requests, top SQL queries, top external requests, etc.
If something new has popped to the top of the list, it could be a red flag that something is wrong. Should that request or query be taking that long? If you check on app performance regularly, you’ll get to know the list of your top transactions and you can immediately tell if something new and unexpected has popped up.
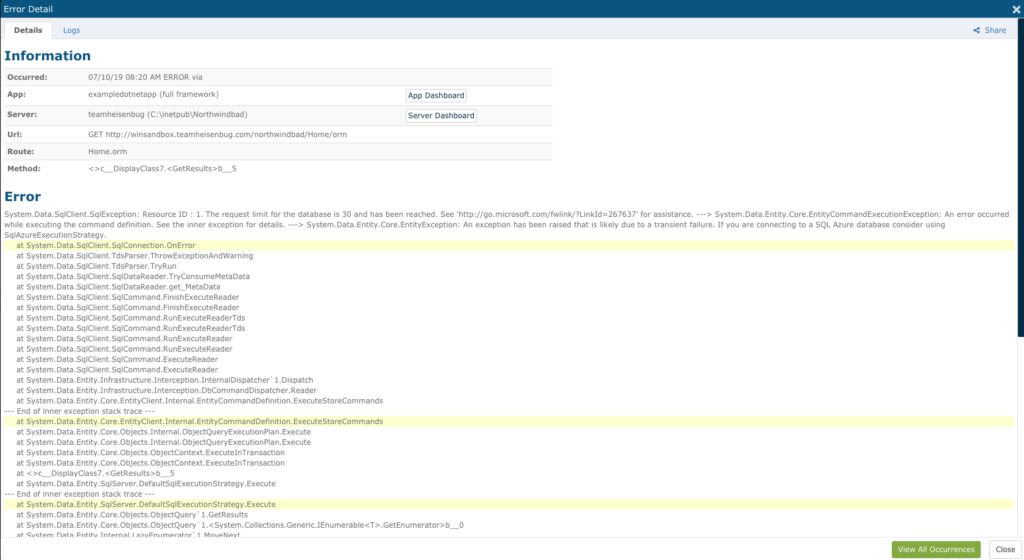
Similarly, a rise in the number of errors in a given area of code could indicate customers are getting error messages or there has been a slowdown in service. An error is actually a good thing because its stack trace lets you zoom straight in on the spot in the code with the problem.
The huge amount of information on the dashboard and performance tabs gives you a lot of insight into how your app is doing and lets you hone in on trouble rapidly. Rapid response is key to reducing MTTR. But it’s also easy to get overwhelmed with all that information. If only you could monitor the crucial pieces that you need to keep an eye on. Guess what? You can!
The app dashboard’s monitoring tab is endlessly configurable. Retrace gives you a wide range of generic server specs to monitor: CPU usage, memory, etc. But it also gives you a plethora of metrics that are tied in with your particular language and framework.
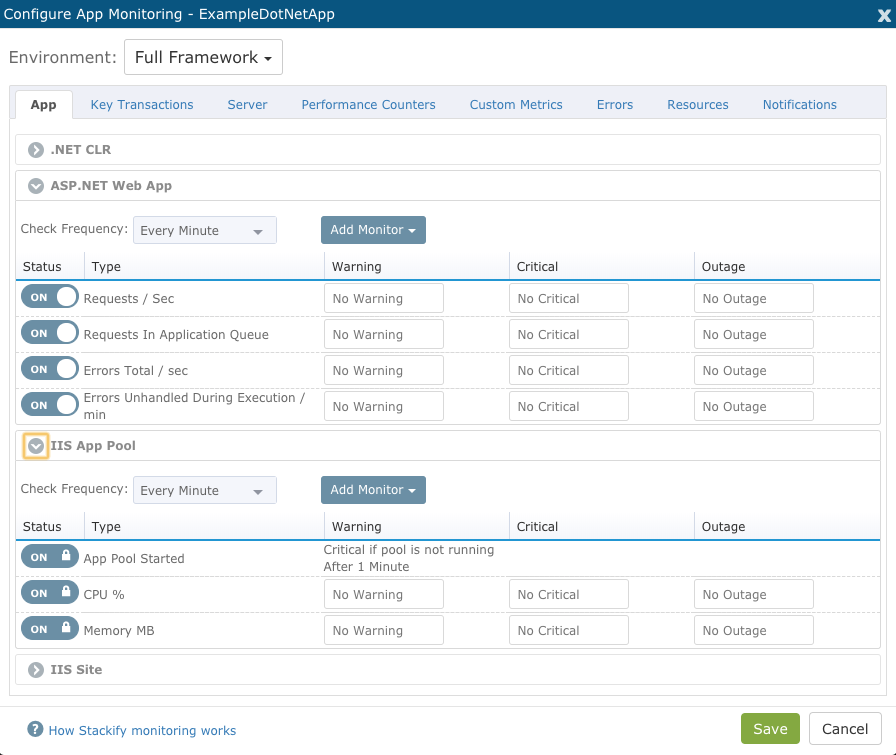
This allows you to completely customize your performance graphs. You can also dial in on what is considered noteworthy or critical. Maybe you have a particular query you need to keep an eye on? And that includes NoSQL databases like Mongo or search engines like Elasticsearch.
You can even set up your own custom dashboards with only the stats you need to watch. The trick is to know what to watch. Each application has its strengths and weaknesses. As you get to know your application’s trouble spots, set up a dashboard to keep an eye on all of them.
Retrace also offers an API to hook into specific spots in your code. You can set up tracked functions that will record performance data for a single function call in your app. How’s that for dialing things in?
You can also configure Retrace to keep a close eye on third-party web services. This is a classic source of trouble for a modern web application. You want to know immediately if a service you’re relying on is down.
It is important to remember, however, not to go overboard setting up monitoring and alerts for all possible data points. That could overwhelm your team with things to watch and generate a lot of alert noise. It’s human nature to tune out if you keep getting notified about things you don’t actually have to respond to. Not to worry though, Retrace lets you set up or turn off all the alerts and notifications.
It’s also important to notify the right people in the right way. Retrace has you covered here as well. It integrates with the popular Jira issue tracker and can actually create a new ticket for you. Similarly, it integrates with Jenkins so that it knows when new code was deployed. It can also put an alert message into a configurable Slack channel, putting the issue right in your face. And of course, there are email and SMS notifications as well.
Once you know there is an issue that needs to be addressed, you want to find the code causing the problem, fix it, and get it deployed to production as fast as possible. This is an essential part of reducing MTTR. Retrace helps you dig right into the flow of a given transaction to see where the issue lies. This is called a transaction trace.
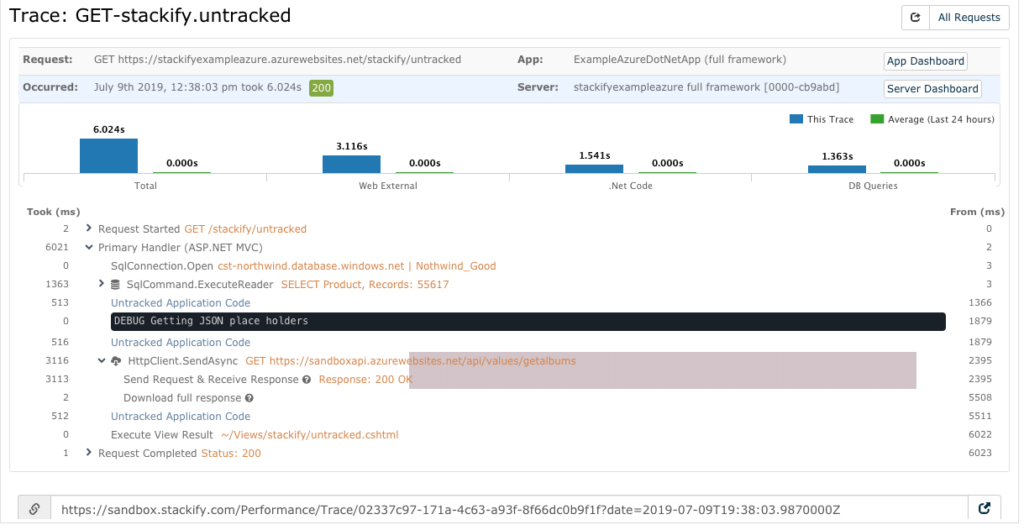
With this breakdown of each phase of the request, you can easily see which part is taking too long or outright breaking. If this is an issue causing a service interruption, you’d want to make a ticket for it and get to work on the fix immediately. Time’s a-wasting!
It’s especially important to keep an eye on your APM service immediately after a deploy. If you have good alerts set up, they might let you know about a problem before you can spot it, but it can’t hurt to be watching.
Also, be sure to compare apples to apples. Is the whole site down or is a certain page just slow? Prioritizing what to fix first will help you keep your customers happy and help your company make more money.
At its most basic, you calculate your MTTR by taking the end time of an outage and subtracting it from the start time. That gives you the duration. Sum up each outage’s duration over a given time period and then divide by the number of issues to get your MTTR. If you deploy small changes frequently, there are fewer things to break with each deployment and it’s easier to keep the MTTR numbers low.
Remember, however, to keep separate MTTR numbers for different levels of seriousness. All members of the team should keep an eye on these numbers and share in a blameless culture of rapid change and rapid recovery. Before you know it, you’ll be an elite DevOps team.

Stackify's APM tools are used by thousands of .NET, Java, PHP, Node.js, Python, & Ruby developers all over the world.
Explore Retrace's product features to learn more.
If you would like to be a guest contributor to the Stackify blog please reach out to [email protected]






