
Performance tuning MySQL depends on a number of factors. For one thing, MySQL runs on various operating systems. For another, there are a variety of storage engines and file formats—each with their own nuances. In this tutorial, you’ll learn how to improve MYSQL performance. But first, you need to narrow the problem down to MySQL.
Let’s say Retrace is reporting a slow page on one of your sites. You’ve gone to the trace for that page in Retrace and you can see that it’s definitely a MySQL call that’s underperforming. Now you know to improve MySQL performance issues but maybe you don’t know where to start looking. So, let’s start at the beginning with the basics.
MySQL is a relational database. Your tables need to be properly organized to improve MYSQL performance needs. To understand what this means, you’ve got to understand the underlying storage and indexing mechanisms. Let’s begin by looking at how the data lives on disk.
MySQL stores data in tables on disk. Of course, there are exceptions, such as in-memory temporary tables. And different storage engines organize data in different ways. Since InnoDB is the default storage engine and has been since 2010, we’ll keep the discussion focused there. It’s worth mentioning that InnoDB boasts several performance improvements over its predecessor, MyISAM. If you’re able to switch from MyISAM to InnoDB, especially for large wide tables, you should notice a performance improvement!
InnoDB stores data in a clustered index. A clustered index sorts the data on disk by one or more of the table’s columns, called the primary key.
For example, take a table with two columns: id and name. You might define the table with the id as the primary key. If it’s auto-generated using the auto_increment option, each inserted row will go at the end of the clustered index like this:
id | name
1 | ...
2 | ...
3 | ...
...
4396 | 'Zak'
4397 | 'Fred'
^ inserted ('Fred')
Fred was added to the end of the table and given the next id after Zak. But, what if we need to insert a record in the middle somewhere? There’s a clever mechanism for that, as with other relational databases. The first step to understanding this is understanding pages.
The clustered index is divided into pages—consecutive blocks of space on the disk. By default, 16 kilobytes of data can be stored in a single page of the InnoDB clustered index. InnoDB organizes the pages into a B+ tree (the + means the leaf nodes point to their neighbors).
Large values are stored off the page in a different location. Storing large values off-page saves space and time in the clustered index. However, doing so can slow down performance if you’re searching through those large values—and even if you aren’t! So it might be better to use a different table for larger objects.
The purpose of a page is to allow space for future data insertion. To achieve this feat, InnoDB attempts to leave 1/16 of the page free for future insertions. But, if you’re inserting out of order (based on the primary key), it will be 1/2 to 1/16 of the page. These gaps on the page help keep the data in order.
The disk has to seek through the records to locate the data. When you have a hard disk drive (HDD), this means spinning the platters and moving the heads to the location. If the data is scattered on the disk, the heads will have to jump around to scan through the tables. So ordering the tables on disk is important.
If you fill up a page, InnoDB will split it into two pages. The new page will end up out of order on disk until the index can be rebuilt, which takes a long time and isn’t done frequently. That means disk reads will no longer happen in order for that section (extent) of data.
And what about a solid-state drive (SSD)?
Use faster drives! SSDs are much faster than HDDs. They’ll cost more so if you’re cost-conscious, you can use a hybrid system. Put large tables that are accessed frequently on SSDs along with their indexes. Then you can put the smaller tables and things like archives or audit tables on platters.
If you really want to geek out on SSDs, this article gives a good rundown of the technology. The professional models use single-level cells (SLC), which means only one transistor per cell. Consumer-grade SSDs have more transistors per cell and are not as fast or durable.
But enough about drives, let’s get back to things you as a programmer have more control over.
We’ve covered enough information about how the data is organized on disk to start talking about something really useful: primary key choice. When it comes to choosing a primary key, you need to understand how your data will be used. There are a few rules about primary keys that will affect your choice.
For one thing, a primary key has to be a unique value. You can’t choose a primary key that will have more than one row with the same value(s), such as first and last name. For another, it can’t have null values. The primary key must be unique and not null. Insert a row with a null or duplicate value and you’ll get an error instead. So, choose wisely! But how?
You want to pick a primary key that’s most commonly used in the queries that matter the most. When you don’t have a unique key, you can add an auto-incremented id column to the table. This is a useful reference for related tables as well as humans. You could also let InnoDB add a hidden one for you. It may do that itself, if you don’t define a primary key!
With other types of primary keys, it helps to keep two things in mind:
And with that, here are some other considerations for primary keys.
A natural key is a single column or combination of columns that are naturally unique and not null. If you have more than one contender, use the one that will show up in the most queries.
For example, if you have a table of users with a username column, chances are you’ll have many queries on that column. Think of the following query:
SELECT name, points, email WHERE username = @username;
This sample query will be called whenever a user logs in. In this case, the table can be ordered on disk by username. The username is a natural primary key. But, remember that a varchar will take more space, especially if you’re employing a character set that uses more than two bits. Also, note that it’s a relatively large undertaking to change the type of primary key. All the foreign key references have to be updated too. Joins against mismatched types are slower than joins against the same type. That’s because MySQL has to convert them in order to make the match.
A combo key consists of more than one column that makes up a primary key. If you do use a combo key, make sure you choose one that will be used in many queries. Otherwise, your efforts, disk space, memory, and processing power will be wasted. Here’s a sample of a combo key in action:
SELECT comment_text, timestamp WHERE username = @username AND post_id = @post_id;
In the comments table, username, post_id, and timestamp are used as the primary key. But there’s a problem: They don’t really make the best key. For one thing, the key will be wide. This means it’ll take up more space on disk and in any indexes on the table and foreign keys that point to this table. For another, you’ll have a lot of inserts in the middle of the clustered index. This means pages will have to be split and they won’t end up in sequential order on disk.
This is a good time to talk about indexing beyond just the primary key.
When it comes to improving MYSQL performance, provided you’ve got your tables situated properly, indexing is vital. Now that we’ve gone over some basics, it’s time to go a bit deeper into this world!
You can create secondary indexes, as they’re called, to improve performance for common or slow-performing queries. It’s not necessary to index a smaller table, but when you have a lot of rows you start to think about this kind of thing. Which columns are used in queries that perform poorly? Those can be indexed to improve performance.
Here’s how it works. Let’s say we have a table with some users, as before:
CREATE TABLE users
(
id INT UNSIGNED AUTO_INCREMENT,
username VARCHAR(100),
given_name VARCHAR(100),
family_name VARCHAR(100),
created_date_utc DATETIME,
modify_date_utc DATETIME,
stars MEDIUMINT UNSIGNED,
PRIMARY KEY(id)
)
You also have some search feature that lets users search for other users. The search looks across username, given_name, and family_name, so your query might resemble this:
SELECT username, given_name, family_name
FROM users
WHERE username LIKE @like_clause
OR given_name LIKE @like_clause
OR family_name LIKE @like_clause
LIMIT @page, @size;
This query will scan the whole table, row by row, looking for matches against the @like_clause. When you have millions of users, this will take a long time. It’ll get even worse when you need to return additional data along with the results from other tables. This example is overly simple, but even still it will benefit from an index. Let’s make one now.
CREATE INDEX users_given_name_IDX USING BTREE ON `_poc2`.users (given_name,family_name,username);
And now, with the index in place, our searches will perform much better. Keep in mind this applies to very large tables since MySQL will perform queries well against smaller tables. That said, it’s important to keep in mind your table width and the data type size. The smaller the better attempting to improve MYSQL performance.
Think before you add secondary indexes since each one causes inserts and updates to perform more slowly. Plus they take up more disk space. You might be able to refactor the existing tables to improve queries instead. And, you’d gain more from the refactor besides a single query’s performance.
If you’re doing any searches where the @like_clause starts with a wildcard, this will slow down your queries considerably. You could opt to use the full-text index, but those aren’t perfect either. Typically you need at least three characters to perform a search. But what if you’re searching for users with the family name “Li”? Arguably, searching might be better reserved for tools that are specifically made for this kind of work. For example, you could use something like Elasticsearch, which employs a Lucene index for efficient searching.
Once indexes are in place, you’ve still got to consider how your queries are structured. How you write your queries makes all the difference when it comes to improving MYSQL performance. A poorly structured query can perform thousands of times slower than a well-written one.
While structure and schema are critical to performance, how you query the data is just as important. The difference between an optimal and suboptimal query can make a 1,000% difference in speed and resource usage. There’s nothing worse than all other queries having to wait on a poorly-performing query while the server is starved for resources. So let’s see where we can address query performance tuning in MySQL.
When it comes to queries, there are some basic issues that are easily avoided. Before getting into some specifics such as sorting and aggregate subqueries, I want to mention a really simple rule of thumb: avoid applying functions to every row in a table in a query.
If you must apply a function, do so after filtering out as many unneeded rows as possible. When you really think about it, this is the basic principle of all performance optimizations. It’s what the MySQL optimizer seeks to do when it creates a plan for your queries. But sometimes it needs your help!
Believe it or not, it matters how you order your columns. Earlier in this post, you saw that indexes speed up queries against the indexed columns. They also speed up sorting by the indexed columns usually. Indexes are sorted ascending only. That doesn’t mean you can’t go forward and backward through the index; you can absolutely walk across the leaves either way. But you can’t walk across the leaves in both directions at once!
In other words, the following sort will go really slowly because it has to use a filesort:
SELECT user, timestamp
FROM comments
ORDER BY user ASC,
timestamp DESC;
You can find out for yourself. Either create a table like this and populate it, or use a table you already have that contains a lot of rows. To see the difference in how the query optimizer will sort the data, use EXPLAIN before the query like this:
EXPLAIN
SELECT user, timestamp
FROM comments
ORDER BY user ASC,
timestamp DESC;
That will get you a query plan that shows which indexes (if any) the optimizer will use along with any “Extra” information. The “Extra” has some key information that contains clues about the query’s performance. “Using index” is good. But, “Using index; Using filesort” will be slow. And this is exactly what you’ll get when you either don’t have the target sort columns in an index or when you sort them in opposite directions.
To make the most out of sorting, make sure the “order by” columns is indexed. Also, make sure you’re sorting in the same direction if you order by more than one column.
There’s one other tip I want to share that dramatically improved a query I was recently tuning. In this case, I needed to get the most recent timestamp of a related record.
We can use users and comments as an example. Let’s say you want a pageable list of users in a web app. They can be sorted, paged, and filtered by some criteria or other. One of the columns should show the date of the user’s most recent comment.
There are a number of approaches you might take to make this happen. You could use a subquery in the select. You could join an aggregated comments table in a subquery. Or you could use an aggregate subquery in the select statement. The aggregate join or the aggregate subquery will perform better in most cases. Here’s an example of how they look:
SELECT
user,
(
SELECT
latest_timestamp
FROM (
SELECT
user_id,
MAX(timestamp) AS latest_timestamp
FROM comments
GROUP BY user_id
) aggregate
WHERE aggregate.user_id = users.id
) AS latest_timestamp
FROM users
ORDER BY username
LIMIT @i, @r;
This one uses an aggregate subquery (called a “DEPENDENT SUBQUERY” by the optimizer output). The joined aggregate subquery should perform even better, especially when you have more users. That query would look like this:
SELECT
user,
aggregate.latest_timestamp
FROM users
LEFT JOIN (
SELECT
user_id,
MAX(timestamp) AS latest_timestamp
FROM comments
GROUP BY user_id
) aggregate
ON aggregate.user_id = users.id
ORDER BY username
LIMIT @i, @r;
The subquery has been moved into a left join (there may not be records for all users). Remember to make sure you have the right indexes in place or you’ll still see performance issues.
The last tip for improving MYSQL performance is useful when you have a bunch of records to save. This might be a comma-separated list of values (CSV list) coming from a file or a UI. You could iterate over the list and save each record one query at a time. This is a slow way and is also known as RBAR (row by agonizing row).
The quick way is to save them all at once—it’s always faster to work in batches in MySQL. There’s no built-in way to send a set of records to a stored procedure all at once. But there is a clunky yet effective workaround. You can pass the CSV list in as a string and parse the values into a temp table. Then the temp table can be used to insert or update the records in the destination table(s).
You’ll need to make your own stored procedure to split the CSV into a temp table. It gets really complex when you need to save more than one attribute per entity. My favorite way to work around this is to convert the CSV list to a list of XML. Simply code each entity into XML and separate by a delimiter such as a comma. Then use a simpler version of the stored procedure to map it into a temp table. Next, use the XML “ExtractValue” function in MySQL to get the values for each column.
Here’s an example where we’re saving two users in one call:
-- input as CSV list with multiple values as XML for each record:
-- @users = '<user><username>1</username><name>Bob</name></user>,
-- <user><username>2</username><name>Sara</name></user>'
call reverse_group_concat(@users);
-- puts each user XML into a row in tempUnCSV table
INSERT records
SELECT
ExtractValue(row, '//username') AS username,
ExtractValue(row, '//name') AS name
FROM tempUnCSV;
There is a limitation with this method. The “reverse_group_concat” procedure gets fairly costly as the string gets longer. Keeping your XML shorter by using single-letter node names will help. For example, “<user>” becomes “<u>” and “<id>” becomes “<i>”. This won’t eliminate the cost completely, but it’ll help. If you notice a significant slowdown after a certain number of records, splitting the save into batches will speed things up a bit. You may have five batch calls to make, but it beats 5,000 calls to do it row by agonizing row!
I want to share a tool that ensures you’re finding slow MySQL queries and are able to easily pinpoint issues. Stackify’s solution, Retrace, shows you how to find slow queries as well as how many times a query has been executed and what transactions are calling it, ensuring you have all the insight you need to improve MYSQL performance.
Easily see which SQL queries take the longest.
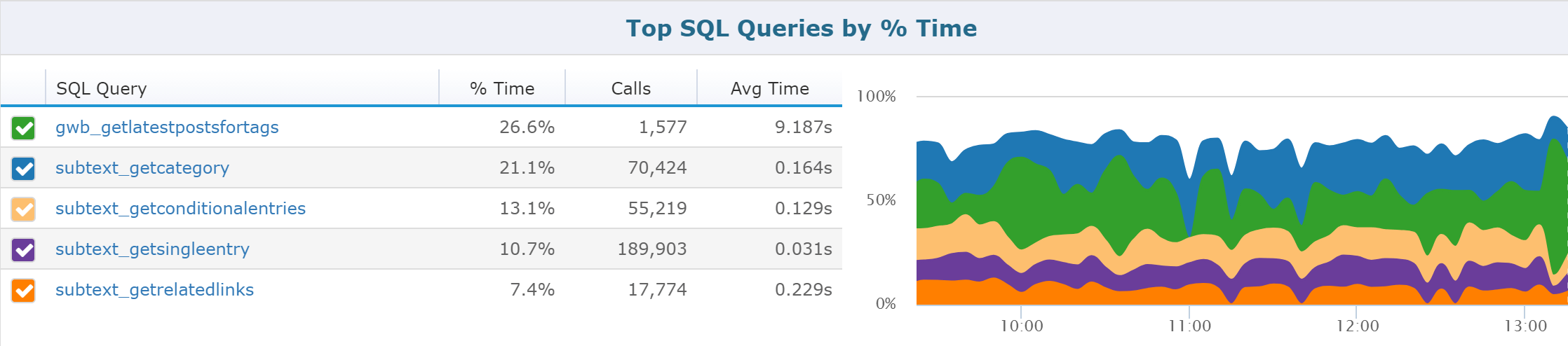
With all the statistics need to improve MYSQL performance in one place, you can simply search for specific queries to hunt down potential problems.
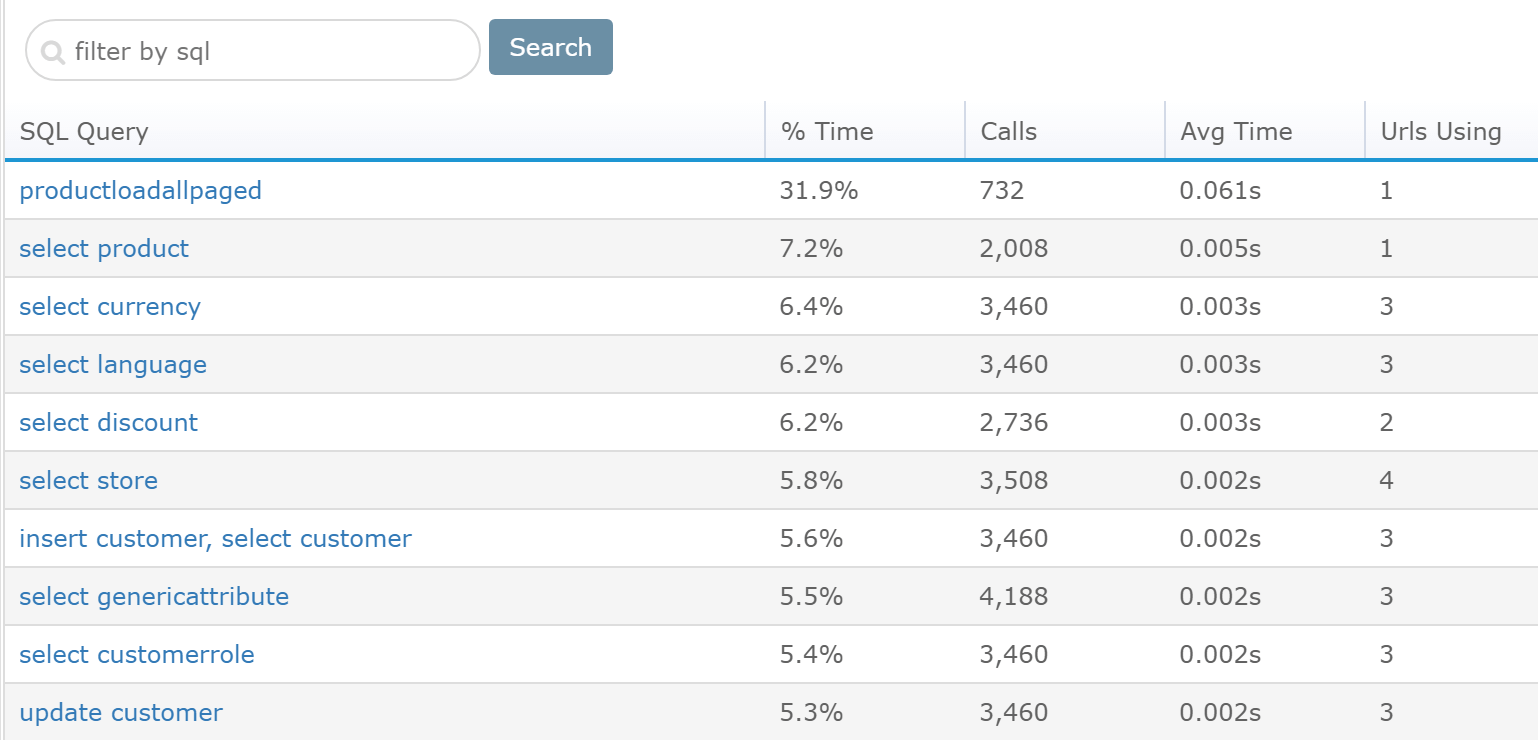
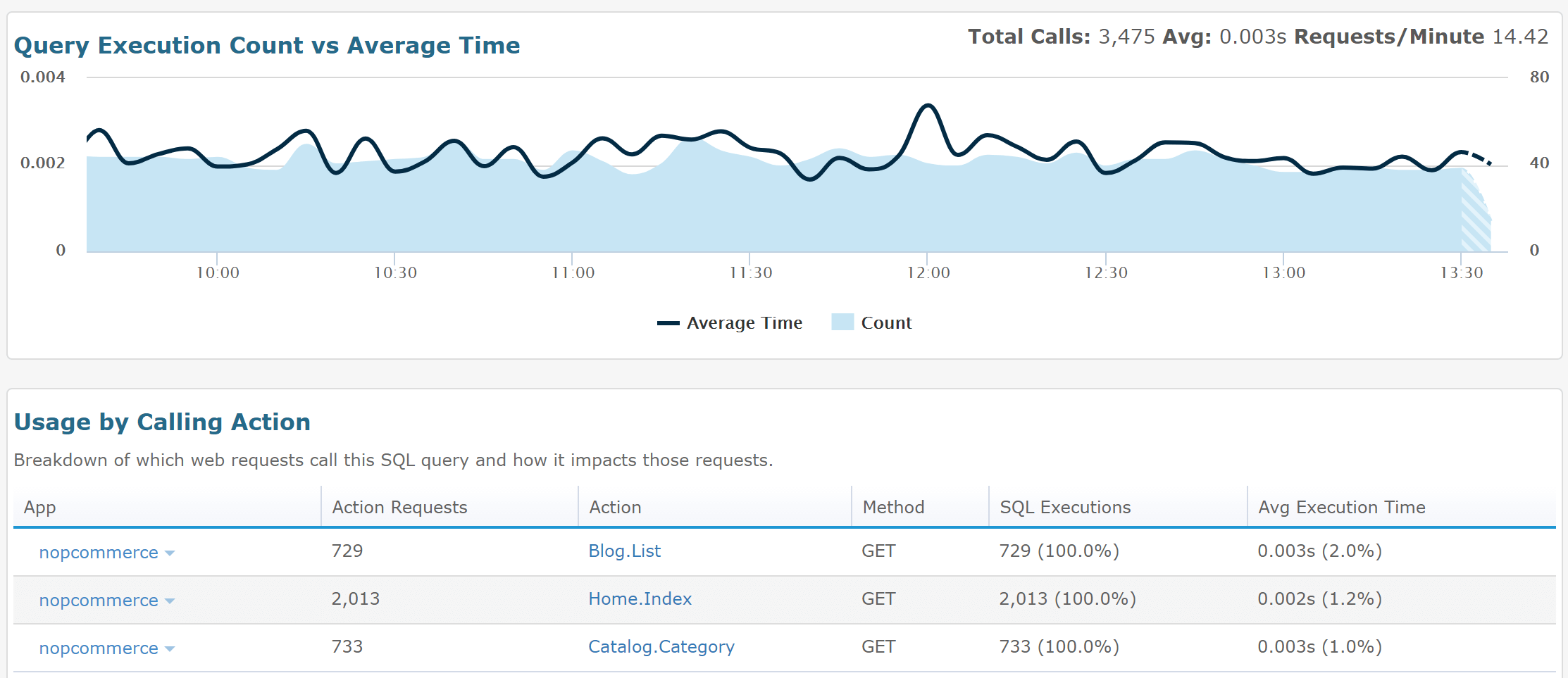
By selecting an individual query, you quickly get insights on how often that query is called and how long it takes as well as what web pages use the SQL query and how it’s impacting their performance.
Don’t take my word for it, just take advantage of the free Retrace trial to see for yourself.
We’ve covered a lot of ground when it comes to improving MYSQL performance, but there are so many more areas to discuss. For example, we haven’t talked much about configurations. MySQL is highly configurable, but most performance-related issues can be solved by using the right table structure, indexing, and optimizing queries.
Of course, when you really need to get the most out of MySQL, or if you’ve got so much active data, you’ll need to go further. Partitioning, managing tablespaces, using separate disks, and routine maintenance will all be a factor. If you want more information, the MySQL documentation links below have a lot of answers for those kinds of fine-tuning questions:
In the meantime, I hope I’ve given you some ideas to better deal with your everyday performance tuning MySQL issues!
Stackify's APM tools are used by thousands of .NET, Java, PHP, Node.js, Python, & Ruby developers all over the world.
Explore Retrace's product features to learn more.









