
DevOps is no longer just about breaking the silo between developers and operations. That’s why every manual operation in your delivery pipeline needs to be evaluated to determine if it can be automated. Database changes are indeed a tedious process and therefore deserve to be considered in your DevOps implementation.
Let me pause a moment to temper your expectations for this post before we continue. I’m not going to give the magic formula that will solve all your problems. Any solution will always depend on how complex and coupled your architecture is, not to mention the rigidity of your change process.
My objective is to give you a different perspective for automating database changes, not just by explaining why database changes can be difficult, but also by walking you through a real-world example of how DevOps can simplify the process. Let’s get started!
Traditionally, changes to the database start with the developers making the changes that they’ll use to write files in a SQL format. These changes are then reviewed by someone with more experience in databases. Usually, the review is done by a database administrator (DBA) who deals with databases all day long. This person understands better than anyone else the implications of some changes—not just in performance, but also in the integration of the data.
Sounds like a solid, necessary process, right? But the problem is that the DBA usually gets involved just before deploying to production when it’s too late and costly to make the proper changes.
I’m not by any means saying that developers need someone else to review what they’re doing. But what I just described is a typical scenario for bigger companies.
DevOps for databases is simply about shifting this process to the left, and automation will make the process run more smoothly. But it’s not just about automation.
There are going to be occasions where you’ll need to do something so complex that automation might not be worth it. But assuming you’ve defined how the database will be used and you aren’t re-architecting, I doubt you’ll need to make complex changes very often. Automation will help you implement future changes in a repeatable and predictable way, so long as they aren’t different every time.
And let’s be honest. Automating the alteration of a table to add a new column is not difficult. The real problem is that, in databases, you need to take care of the state. If the database has too much data, doing a certain type of change could take too much time and block all upcoming changes like inserts, updates, or deletes.
Automation is just one of many changes you need to include in your DevOps implementation. And I might even go so far as to say it could be the easiest part. So always make the case for automating changes, and avoid doing manual changes as often as possible.

Database changes lack a consistent standard because every engine has a different way of managing them. The impact of those changes also varies from engine to engine. For example, SQL Server indexes are not impacted in the same way Oracle or MySQL indexes are.
Structured Query Language (SQL) might be the only thing database engines have in common. But even then, statements provide different results.
In the future, we in the industry might have an easier time because we’ve standardized the way we deal with databases. But in the meantime, make sure you plan ahead for how the database engine could change. You could make use of object-relational mapping (ORM) frameworks and other tools to ease the job. I’ll give you some examples in a later section of this post.
Most of the time, problems in databases are due to how the system is architected.
When you have a tightly coupled architecture with a database at the center…well, you have more serious problems than including database changes in your DevOps implementation. Nowadays, with distributed systems becoming the norm, there are architecture patterns like microservices that have solved the database coupling by giving each microservice its own database.
Microservices are a good way to decouple the database. The only way other microservices interact with the data is by using the exposed methods from the service, rather than going directly to the database—even if it’s possible and “easier” to do it that way.
When you only use the database for storage purposes, changes become easier. Sure, the reason you’re storing the data is to analyze it. That’s why, in some projects I’ve worked, we moved the data to a data warehouse where changes would be rare. We left transactional data with just the data that’s needed. What I just described is better known as the CQRS architecture pattern. We had the data for a week or a month in some cases.
Another important aspect of DevOps for databases is the change in culture and processes that are needed.
Leaving the review of database changes at the end of the workflow is a sign of poor communication between teams. Maybe it’s simply that the teams don’t have the same goals in mind. Or it might be an ego problem where people think they don’t need help and the process is just a blocker.
You no longer have to wait for DBAs to review the changes until the final phase; they need to be involved as soon as possible in the process. As time goes by, developers, operations, and DBAs will be in agreement on how to properly make changes in the database. And the more the team practices the review process, the smoother it will be.
When there’s anticipated collaboration between teams, good things can emerge—and you should make it one of your main goals that everyone recognizes that.
We just talked about how databases tend to be a particular problem in DevOps and how things can be better. But there are also technical practices that will boost your DevOps implementation with database changes.
Migrations are scripts that include database changes that ideally are idempotent, meaning that no matter how many times you run the script, the changes will only be applied once. It’s also better to have the scripts in version control so you can keep track of the changes and go back and forth with changes more easily.
In other words, migrations are database changes as code. You can run the exact same migrations in different environments and the results should be the same, starting with the local environment—the developer’s machine.
Let’s talk about another technical practice that’s easy to implement but takes a little discipline: testing.
You need to test a change before applying it to a production environment. If the table data is huge—so huge that it would be costly to replicate it in a different environment from production—make sure you can at least simulate the change with a significant set of data. This will help ensure the change won’t take forever and you won’t be blocking a table for a long period of time.
Containers are a good way to practice. They’re easy and cheap, and if something goes wrong, you can throw everything out and start over.

We can’t keep talking about databases without mentioning some tools. There are a lot of tools out there, and new ones are released every now and then. But are some of the most popular ones and some I’ve used before. Here’s the list, in no particular order:
And besides tools for database engines, there are frameworks that support migrations too:
As an example, let’s get our hands dirty with Entity Framework in .NET Core.
Even though there are a number of powerful tools to automate database changes, let’s take a look at one approach that you can easily automate with tools like Jenkins or VSTS by using Entity Framework (EF) for .NET Core applications.
I’ve built a sample application using the Contoso University project that you can clone from GitHub. We could create an application from scratch, but let’s use this one so we can focus exclusively on the database changes.
We’ll make a simple change just so you can see how EF comes into play.
Let’s start by opening the project with Visual Studio (VS). You’ll need to have .NET Core installed, and you’ll run the application using the IIS Express option. You need a SQL Server instance so you can either install/configure one or use an existing installation of SQL Server. The idea is that you’ll be able to see how the changes are being applied in the database as you progress.
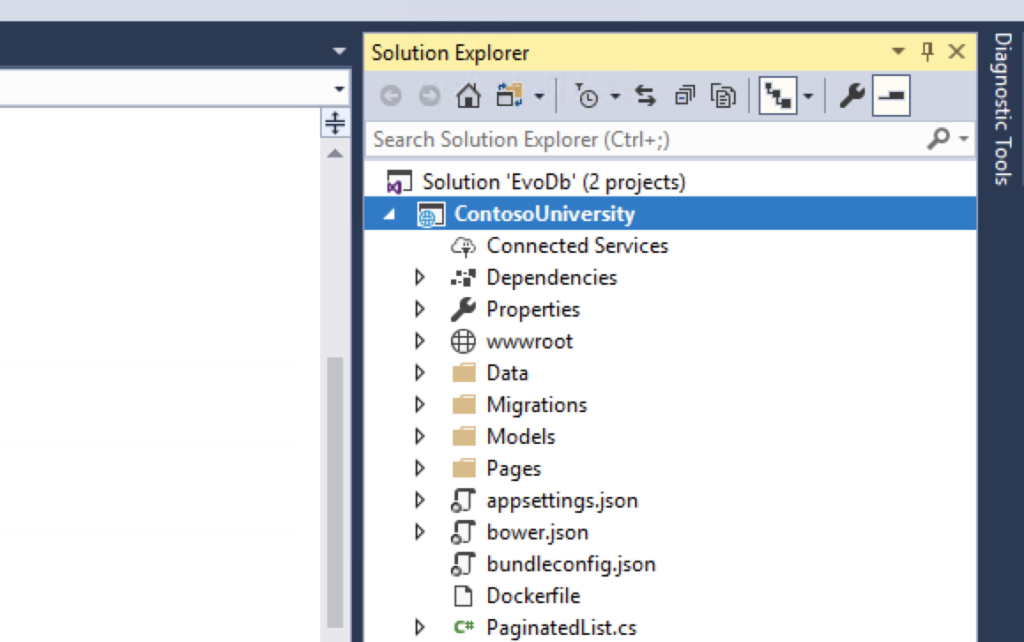
Let’s start by changing some input parameters to avoid spinning up the database when the application gets launched. We’ll do that manually by using the EF migration commands. Open the properties of the project by right-clicking on the project “ContosoUniversity” and change the debug parameters so that they look like this:
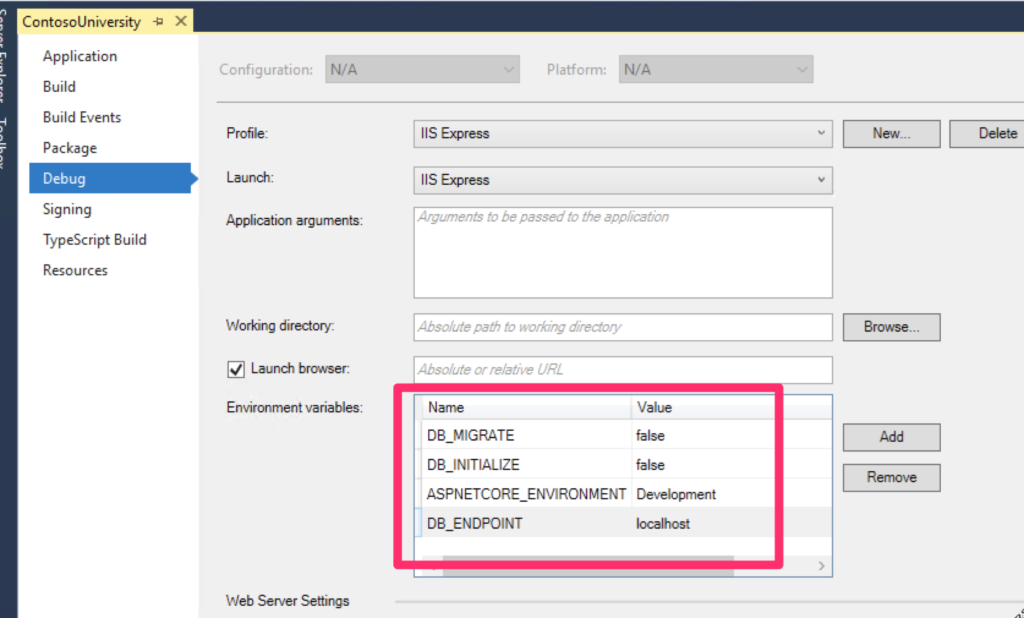
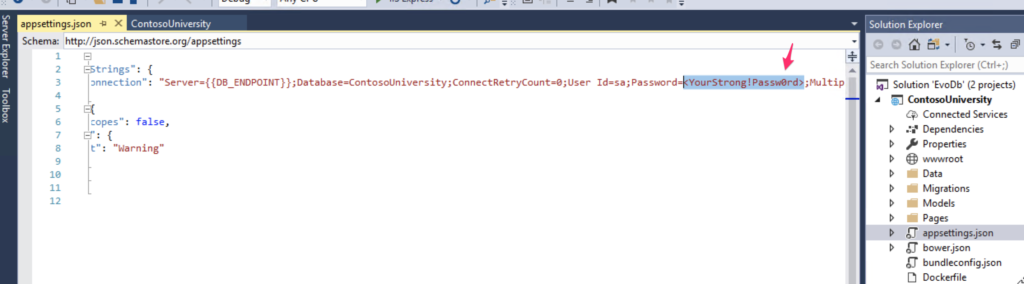
Make sure you have the proper configuration for connecting to the database, especially the database password. You can change the password in the file appsettings.json. Mine looks like this:
Select the “ContosoUniversity” project and then run it by clicking on the “Debug” button. Even if the application starts, it won’t work because the database doesn’t exist—we haven’t run the first migration that creates the database.

Let’s open a terminal. You can even use the command line included in VS. Run the following command in the project root folder so that EF creates the database schema.
dotnet ef database update
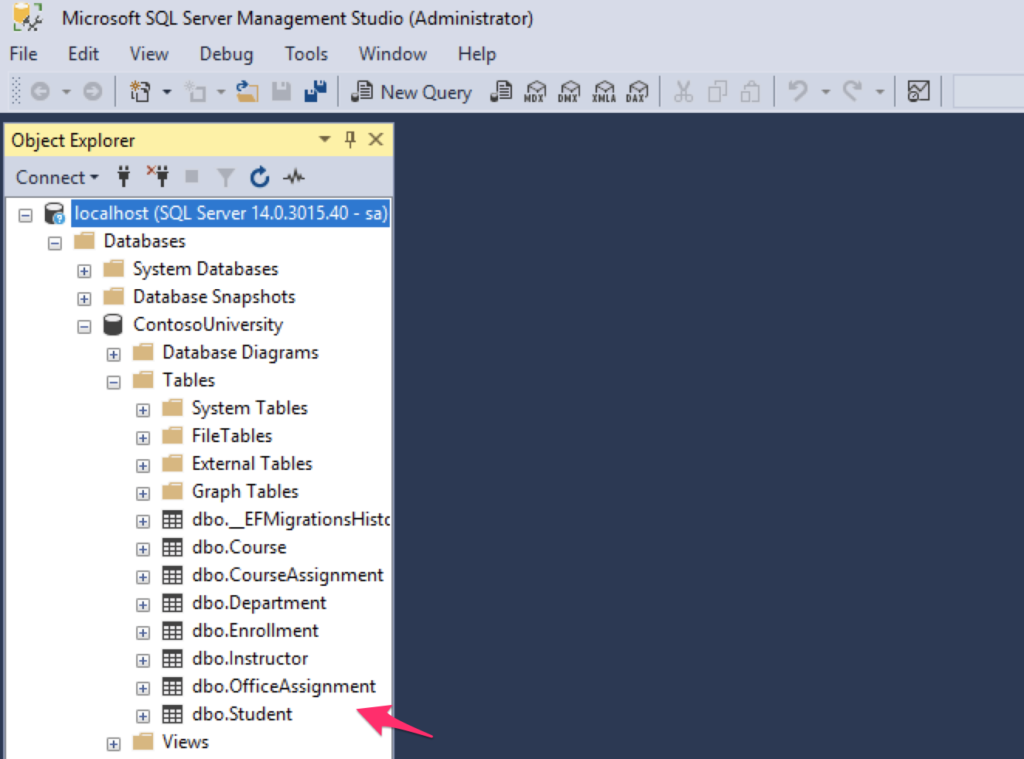
Now you can connect to the database and check that all the necessary tables have been created.
Now let’s make a change in the application by adding a new column. To do so, go to the file Models/Student.cs and add the column. It should look like this:
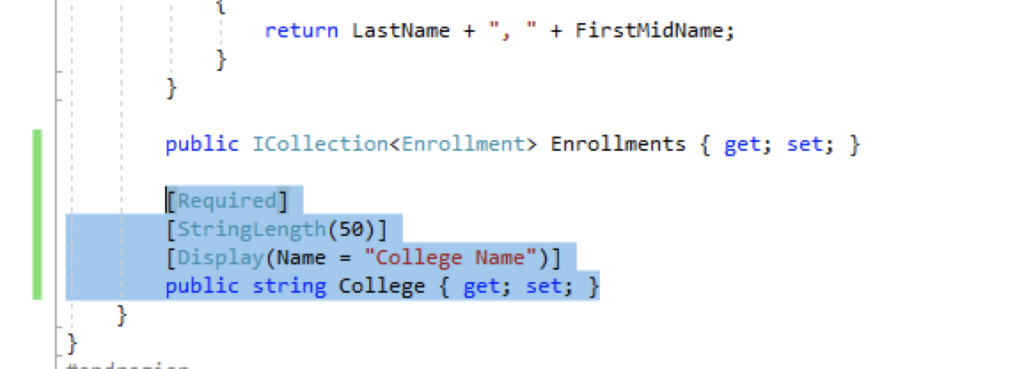
Now go to the view and add the column so that it’s easy to see the change.
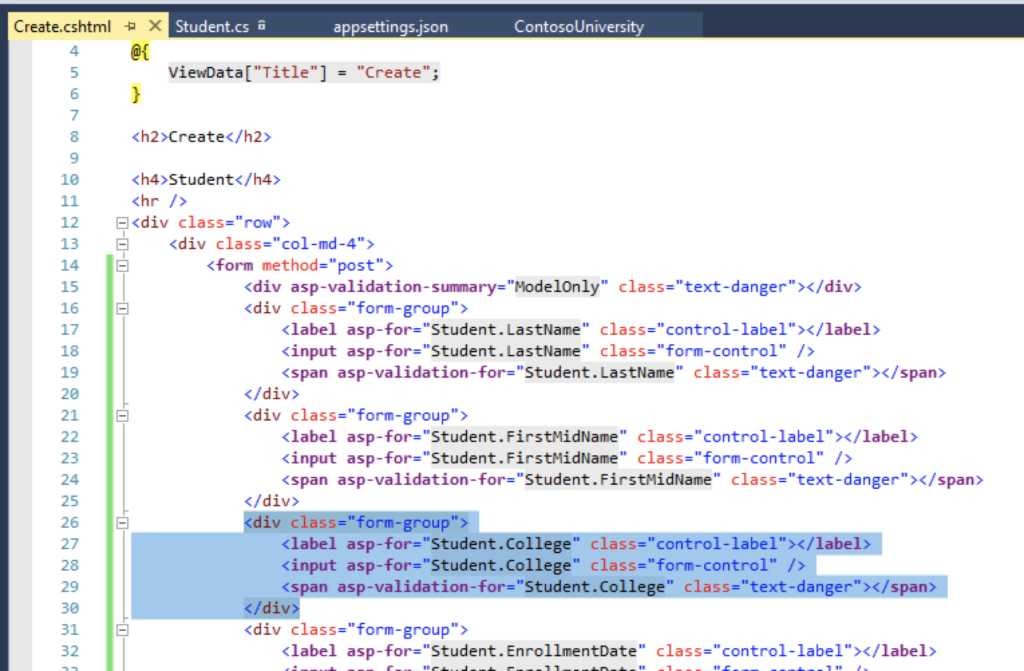
And for to persist the new column, you need to change the code of the “View” in the file Create.cs, like this:
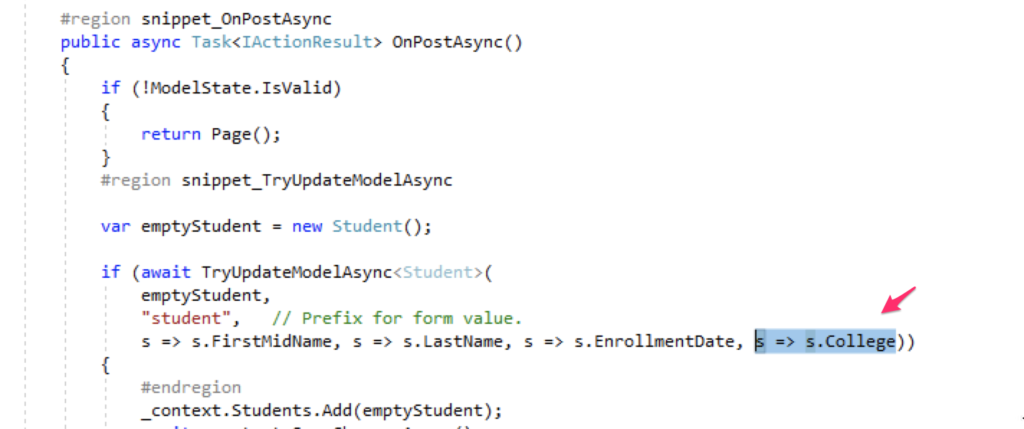
Before you run the application again, let’s create the migration in EF so the next time you run the database update, EF will run any pending migration. To do so, run the following command:
dotnet ef migrations add AddStudentCollege
Explore the solution a bit and you’ll see that a new file is created with all the details of the migration. And remember, too, that we mentioned we needed to have these changes versioned.
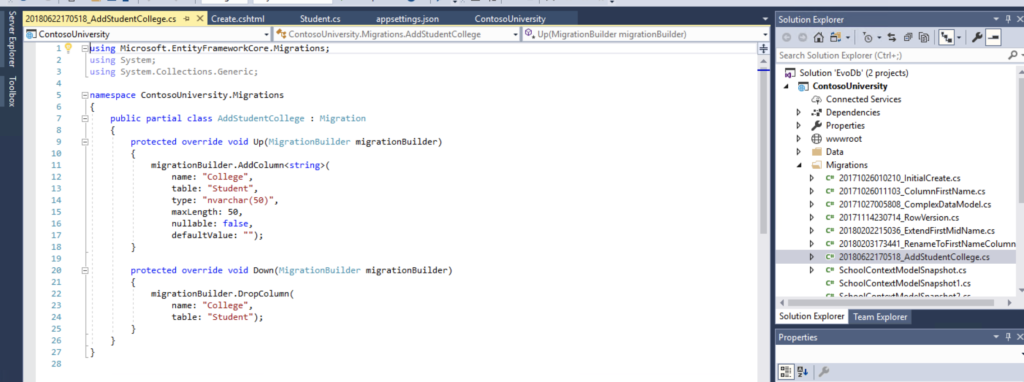
Run the application again. The UI will be updated, but it won’t work because the database hasn’t been updated yet. Let’s run the update command again to apply any pending migration.
dotnet ef database update
Refresh the application. It should be working now.
Next time you or someone else needs to do a change, a new migration will be created. Applying it is just a matter of running the update EF command again. Of course, as you get used to it, you’ll be better at automating database changes. Remember, DevOps for databases involves much more than technical practices.
It’s also possible to revert any change in the database after you’ve updated the destination database with recent migrations. To do so, you just run the following command:
dotnet ef migrations remove
It will remove the latest migration. That means that if more than one of the migrations is applied, this command will remove only the most recent one. You’ll need to run the command again to keep reverting database changes.
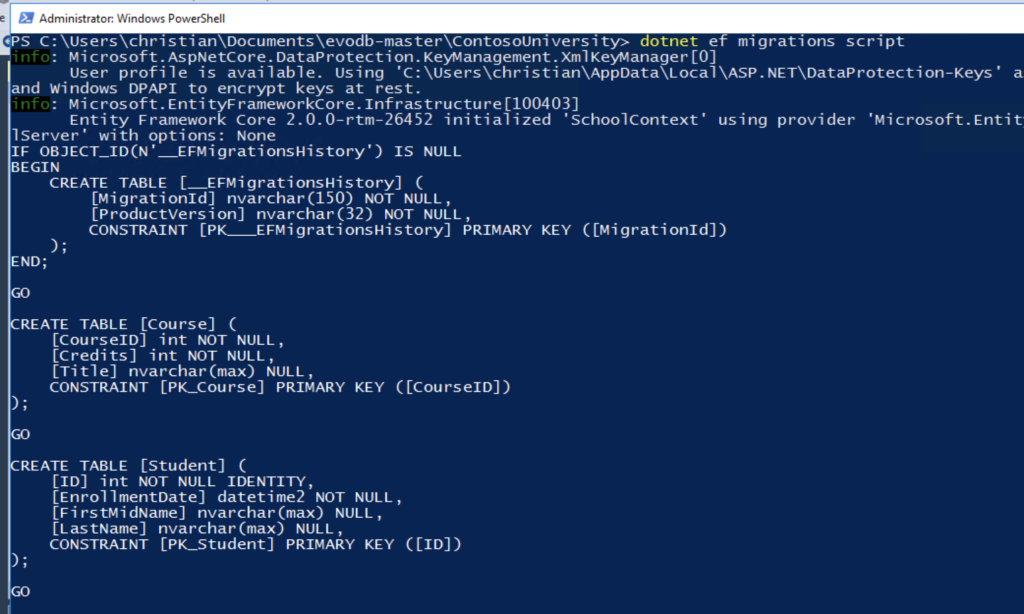
When you’re still adjusting to this process, you might want to check exactly what EF is doing in the database before applying any change. Well, you can review the changes in a SQL format. EF has a command to generate the scripts in a SQL format that any DBA will understand.
To generate the migrations in a SQL format, let’s run the following command:
dotnet ef migrations script
All the SQL statements you need are going to appear in the terminal. You can then store the output in a file for a later review.
And that’s it! Now that you’ve practiced this on your machine, you’re ready to automate this new process using Jenkins or VSTS. You’ll just need to run the update command in the deployment pipeline after the application has been deployed. The developers are the ones that will use the other command to generate the migrations and put them under version control.
As you’ve seen, there’s no magic formula that I can give you to implement DevOps for databases. There are too many things involved. But the first step is to be willing to get out of your comfort zone and do things better.
Embrace the change. I know it’s scary, especially when we’re talking about data. Try to keep things as simple as possible from process to architecture. Focus on having a decoupled architecture that allows you to make changes without too many hassles. And educate yourself! I highly recommend this post by Martin Fowler as a place to start.
Changes in the database are not difficult per se; the problem is the implications of potentially losing/damaging all or a portion of the data. Repetition and consistency are key, which is why you need to practice before going live—not just before deploying to production.
Keep your databases running smoothly with Stackify’s Application Peformance Management tool, Retrace. Download your free two week trial today!
Stackify's APM tools are used by thousands of .NET, Java, PHP, Node.js, Python, & Ruby developers all over the world.
Explore Retrace's product features to learn more.









